
Pregled algoritama neuronske mreže
- Prvo upoznajmo što znači neuronska mreža? Neuronske mreže potiču biološke neuronske mreže u mozgu ili možemo reći živčani sustav. To je generiralo puno uzbuđenja, a istraživanje i dalje traje na ovom podskupu Strojno učenje u industriji.
- Osnovna računarska jedinica neuronske mreže je neuron ili čvor. On prima vrijednosti od drugih neurona i izračunava izlaz. Svaki čvor / neuron povezan je s težinom (w). Ta se težina daje prema relativnoj važnosti određenog neurona ili čvora.
- Dakle, ako uzmemo f kao funkciju čvora, tada će funkcija čvora f pružiti izlaz kao što je prikazano u nastavku: -
Izlaz neurona (Y) = f (w1.X1 + w2.X2 + b)
- Gdje su w1 i w2 težina, X1 i X2 su numerički ulazi, a b je pristranost.
- Gornja funkcija f je nelinearna funkcija koja se također naziva i funkcija aktiviranja. Njegova je osnovna svrha uvesti nelinearnost, jer su gotovo svi podaci u stvarnom svijetu nelinearni i želimo da neuroni nauče te reprezentacije.
Različiti algoritmi neuronske mreže
Pogledajmo sada u četiri različita algoritma neuronske mreže.
1. Gradijentski silazak
To je jedan od najpopularnijih algoritama za optimizaciju u području strojnog učenja. Koristi se tijekom obuke modela strojnog učenja. Jednostavnim riječima, u osnovi se koristi za pronalaženje vrijednosti koeficijenata koji naprosto smanjuju troškovnu funkciju koliko god je to moguće. Prvo od svega, započinjemo definiranjem nekih vrijednosti parametara, a zatim pomoću računice počinjemo iterativno podešavati vrijednosti tako da smanjuje se izgubljena funkcija.
E sad, idemo na dio koji je nagib? Dakle, gradijent znači da će se izlaz bilo koje funkcije mijenjati mnogo ako smanjimo ulaz malo ili drugim riječima, možemo ga nazvati nagibom. Ako je nagib strm, model će brže učiti na sličan način model prestaje učiti kad je nagib jednak nuli. To je zato što je to algoritam minimiziranja koji minimizira zadani algoritam.
Ispod formule za spuštanje nagiba prikazana je formula za pronalazak sljedećeg položaja.
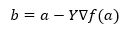
Gdje je b sljedeća pozicija
a trenutni položaj, gama je funkcija čekanja.
Dakle, kao što vidite spuštanje gradijentom vrlo je zvučna tehnika, ali postoje mnoga područja u kojima padanje nagiba ne radi pravilno. Ispod su neki od njih:
- Ako se algoritam ne izvrši pravilno, tada možemo naići na nešto poput problema nestajanja gradijenta. To se događa kada je gradijent premalen ili prevelik.
- Do problema dolazi kada raspored podataka predstavlja ne-konveksni problem optimizacije. Gradient dostojan djeluje samo s problemima koji su konveksno optimizirani problem.
- Jedan od vrlo važnih čimbenika koje treba tražiti tijekom primjene ovog algoritma su resursi. Ako smo za aplikaciju imali manje memorije, trebali bismo izbjegavati algoritam spuštanja nagiba.
2. Newtonova metoda
To je algoritam optimizacije drugog reda. Nazvan je drugim redom jer koristi Hessovu matricu. Dakle, Hessova matrica nije ništa drugo do kvadratna matrica parcijalnih derivata drugog reda skalarno utemeljene funkcije. U Newtonovom algoritmu za optimizaciju metode primjenjuje se na prvi derivat dvostruke diferencirane funkcije f tako da može pronaći korijene / stacionarne točke. Pogledajmo sada korake koje Newtonova metoda zahtijeva za optimizaciju.
Prvo procjenjuje indeks gubitka. Zatim provjerava jesu li kriteriji zaustavljanja istiniti ili netačni. Ako je netočno, onda izračunava Newtonov smjer treninga i brzinu treninga, a zatim poboljšava parametre ili težinu neurona i opet se nastavlja isti ciklus. Dakle, sada možete reći da je potrebno manje koraka u usporedbi s padom gradijenta kako bi se postigao minimum vrijednost funkcije. Iako je potrebno manje koraka u usporedbi s algoritmom za spuštanje na gradijent, računalo je da je točan izračun hessiana i obrnuto, a računi vrlo skupi.
3. Konjugirajte gradijent
To je metoda koja se može smatrati nečim između padova gradijenta i Newtonove metode. Glavna razlika je u tome što ubrzava sporu konvergenciju koju obično povezujemo s padom gradijenta. Druga važna činjenica je da se može koristiti i za linearne i za nelinearne sustave i to je iterativni algoritam.
Razvili su ga Magnus Hestenes i Eduard Stiefel. Kao što je već spomenuto da stvara bržu konvergenciju od silaznog gradijenta, razlog zašto je to moguće je taj što se u algoritmu Konjugate gradijenta traži zajedno s konjugiranim smjerovima, zbog kojih se konvergira brže od algoritama za spuštanje gradijenta. Važna točka koja se mora napomenuti jest da se γ naziva konjugirani parametar.
Smjer treninga se povremeno resetira na negativan nagib. Ova metoda je učinkovitija od silaznog gradijenta u treningu neuronske mreže jer ne zahtijeva Hessonovu matricu koja povećava računsko opterećenje i konvergira se brže od silaznog gradijenta. Prikladno je koristiti u velikim neuronskim mrežama.
4. Quasi-Newtonova metoda
To je alternativni pristup Newtonovoj metodi, kao što smo sada svjesni da je Newtonova metoda računski skupa. Ova metoda rješava te nedostatke do te mjere da umjesto izračuna Hessove matrice i zatim izračunavanja obrnuto, ova metoda stvara aproksimaciju za inverzni Hessian pri svakoj iteraciji ovog algoritma.
Sada se ta aproksimacija izračunava pomoću podataka iz prvog derivata funkcije gubitka. Dakle, možemo reći da je to vjerojatno najprikladnija metoda za rad s velikim mrežama jer štedi vrijeme računanja, a ujedno je i brži od gradijentnog ili srodnog gradijenta.
Zaključak
Prije nego što završimo s ovim člankom, usporedimo proračunsku brzinu i memoriju za gore spomenute algoritme. Prema zahtjevima memorije, zalijevanje u nagibu zahtijeva najmanje memorije, a ujedno je i najsporije. Suprotno toj Newtonovoj metodi, potrebna je veća računska snaga. Stoga, uzimajući sve to u obzir, Quasi-Newtonova metoda je najprikladnija.
Preporučeni članci
Ovo je vodič za algoritme neuronske mreže. Ovdje ćemo također raspravljati o pregledu algoritma neuronske mreže i četiri različita algoritma. Možete i proći naše druge predložene članke da biste saznali više -
- Strojno učenje i neuronska mreža
- Okviri strojnog učenja
- Neuronske mreže vs duboko učenje
- K- znači algoritam klasteriranja
- Vodič za klasifikaciju neuronske mreže