

Pregled aplikacija Kafka
Jedno od trendova u IT industriji je Big Data, gdje se tvrtka bavi velikom količinom podataka o klijentima i dobiva korisne uvide koji pomažu u njihovom poslovanju i pružaju klijentima bolju uslugu. Jedan od izazova je rukovanje i prijenos ovih velikih količina podataka s jednog kraja na drugi radi analize ili obrade. Tu se u igru pojavljuje Kafka (pouzdan sustav za razmjenu poruka) koji pomaže u prikupljanju i prijenosu ogromne količine podataka u stvarnom vremenu. Kafka dizajnirana je za distribuirane sustave velike propusnosti i dobra je pogodnost za aplikacije za obradu velikih razmjera. Kafka podržava mnoge današnje najbolje komercijalne i industrijske aplikacije. Potražnja je stručnjaka za Kafku koji imaju snažne vještine i praktično znanje.
U ovom ćemo članku naučiti o Kafki, njezinim značajkama, slučajevima uporabe i razumjeti neke zapažene aplikacije tamo gdje se koristi.
Što je Kafka?
Apache Kafka razvijen je u LinkedInu, a kasnije je postao open-source projekt Apache. Apache Kafka je brzi sustav grešaka, skalabilan i distribuirani sustav za razmjenu poruka koji omogućava komunikaciju između dva entiteta, tj. Između proizvođača (generator poruke) i potrošača (primatelj poruke) koristeći temeljene na porukama i pruža platformu za upravljanje svim feedovi podataka u stvarnom vremenu.
Značajke koje Apache Kafka čine boljim od ostalih sustava za razmjenu poruka i primjenjivim na sustave u stvarnom vremenu su njegova visoka dostupnost, neposredni, automatski oporavak od kvara na čvoru i podržava slanje poruka s malim kašnjenjem. Ove značajke Apache Kafke pomažu u njezinoj integraciji s velikim podatkovnim sustavima i čini ga idealnom komponentom za komunikaciju. 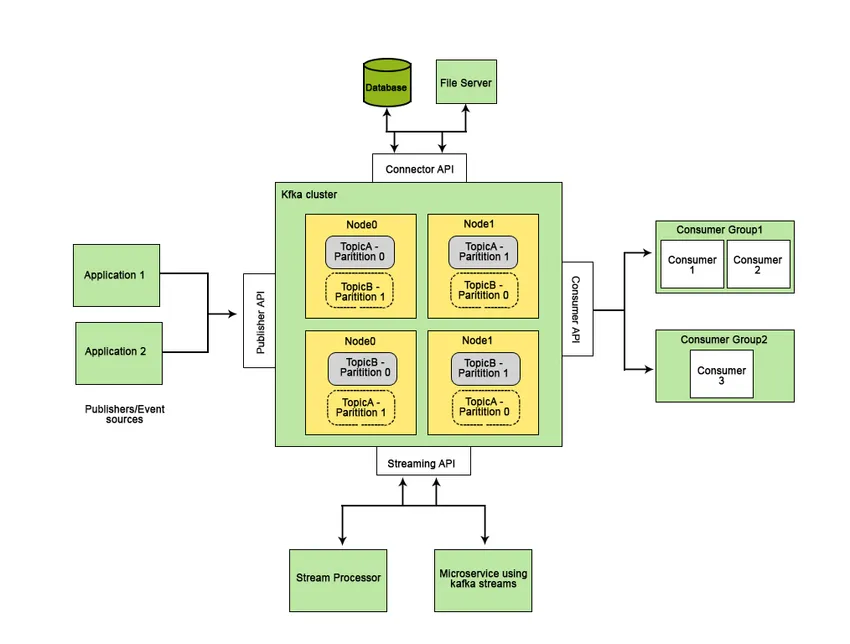
Vrhunske aplikacije Kafka
U ovom ćemo dijelu članka vidjeti neke popularne i široko implementirane slučajeve upotrebe i vidjeti neke implementacije Kafke u stvarnom životu.
Aplikacije u stvarnom životu
1. Twitter: Aktivnost obrade struje
Twitter je platforma za društvene mreže koja koristi Storm-Kafka (alat za obradu otvorenih izvora) kao dio svoje infrastrukture za obradu tokova, gdje se ulazni podaci (tweetovi) troše za agregaciju, transformacije i obogaćivanje za daljnju potrošnju ili praćenje aktivnosti obrade.
2. LinkedIn: Obrada struje i metrike
LinkedIn koristi Kafka za streaming podataka i za operativne aktivnosti mjernih podataka. LinkedIn koristi Kafku za dodatne funkcije kao što je Newsfeed za konzumiranje poruka i provođenje analize primljenih podataka.
3. Netflix: Praćenje u stvarnom vremenu i obrada struje
Netflix ima vlastiti okvir za gutanje koji ubacuje ulazne podatke u AWS S3 i koristi Hadoop za pokretanje analitike video potoka, korisničkih sučelja, događaja za poboljšanje korisničkog iskustva i Kafka za unos podataka u stvarnom vremenu putem API-ja.
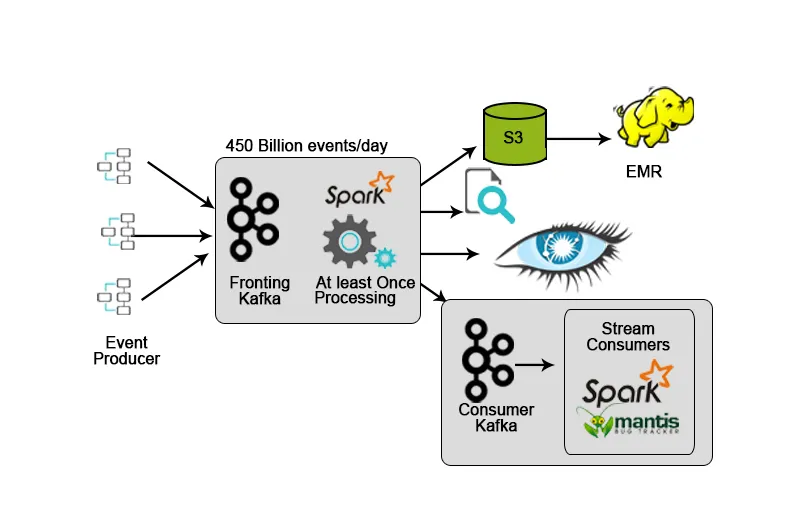
4. Hotstar: Obrada struje
Hotstar je predstavio vlastitu platformu za upravljanje podacima - Bifrost na kojoj se Kafka koristi za streaming podataka, nadzor i praćenje ciljeva. Zbog svoje skalabilnosti, dostupnosti i mogućnosti kašnjenja, Kafka je bio idealan izbor za obradu podataka koje Hotstar platforma generira svakodnevno ili bilo kojim posebnim prigodom (live streaming bilo kojeg koncerta ili bilo koji sportski meč uživo, itd.) Gdje količina podataka se značajno povećava.
Apache Kafka se većinu vremena koristi kao građevni blok za razvoj arhitekture streaming podataka. Ova vrsta arhitekture koristi se u aplikacijama kao što su prikupljanje dnevnika proizvoda / poslužitelja, analiza klikovnog toka i dobivanje podataka iz strojno generiranih podataka.
Ali zajedno s Kafkom, moramo koristiti dodatna sredstva ili alate za pretvaranje dobivenog toka podataka u smislene podatke koji pomažu u dobivanju uvida koji se mogu koristiti u odlukama na temelju podataka. Na primjer, možda ćemo trebati generirati uvid iz sirovih podataka dobivenih s IoT uređaja ili podataka dobivenih s platformi društvenih medija u stvarnom vremenu te izvršiti neku analizu ili obradu i prikazati je poslu kako bi donijeli bolje odluke ili im pomogli da se poboljšaju obavljanje njihovih usluga.
Za ove vrste upotrebe, mi bi trebali usmjeravati naše ulazne podatke / neobrađene podatke u podatkovno jezero, gdje možemo pohraniti naše podatke i osigurati kvalitetu podataka bez ometanja performansi.
Drugačija je situacija, možda čitamo podatke izravno s Kafke, kada nam je potrebna krajnje mala krajnja kašnjenja, poput punjenja podataka aplikacijama u stvarnom vremenu.
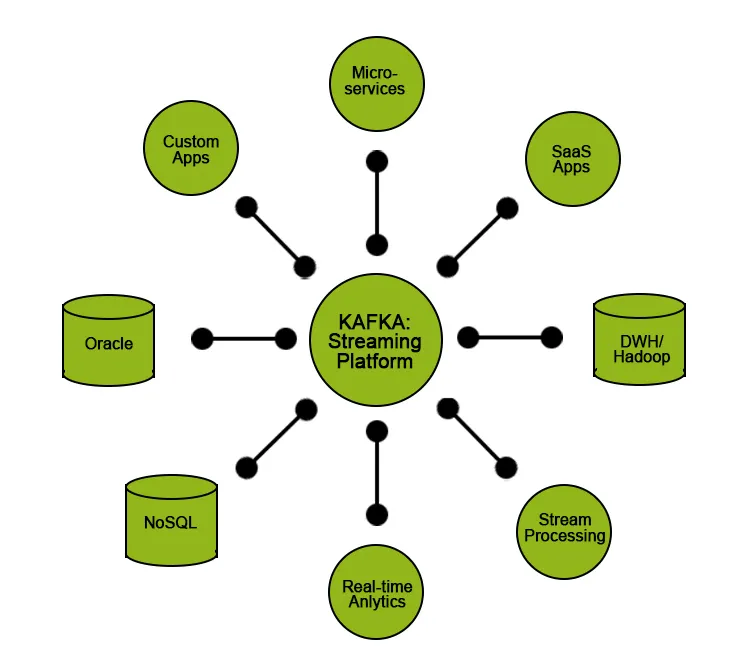
Kafka svojim korisnicima pruža određene funkcionalnosti:
- Objavite i pretplatite se na podatke.
- Pohranite podatke redoslijedom kojim su učinkovito generirani.
- Obrada podataka u stvarnom vremenu i u pokretu.
Kafka se većinu vremena koristi za:
- Implementacija on-the-fly streaming podataka cjevovoda koji pouzdano dobivaju podatke između dva entiteta u sustavu.
- Implementacija aplikacija u pokretu za streaming koji transformiraju ili manipuliraju ili obrađuju protoke podataka.
Koristite slučajeve
Slijedi nekoliko primjera široke primjene aplikacije Kafka:
1. Poruke
Kafka djeluje bolje od ostalih tradicionalnih sustava za razmjenu poruka poput ActiveMQ, RabbitMQ itd. Za usporedbu, Kafka nudi bolju propusnost, ugrađenu particiju, mogućnosti replikacije i toleranciju na greške, što ga čini boljim sustavom za razmjenu poruka za aplikacije velikih razmjera,
2. Praćenje aktivnosti web mjesta
Korisničke aktivnosti (prikazi stranica, pretrage ili bilo koje radnje učinjene) mogu se pratiti i hraniti radi praćenja ili analize u stvarnom vremenu putem Kafke ili koristiti Kafka za spremanje ove vrste podataka u Hadoop ili skladište podataka za kasniju obradu ili manipulaciju. Praćenje aktivnosti generira ogromnu količinu podataka koju je potrebno prenijeti na željeno mjesto bez ikakvog gubitka podataka.
3. Agregiranje zapisnika
Skupljanje dnevnika proces je prikupljanja / spajanja fizičkih datoteka dnevnika s različitih poslužitelja aplikacije u jedno spremište (datotečni poslužitelj ili HDFS) radi obrade. Kafka nudi dobre performanse, niže kašnjenje od kraja do kraja u odnosu na Flume.

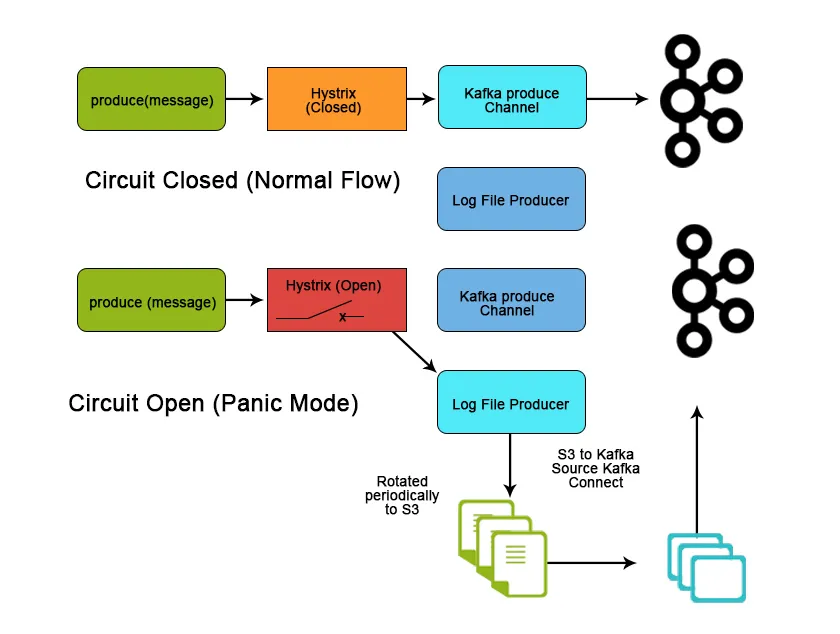
Zaključak
Kafka se uvelike koristi u velikom prostoru podataka kao način za brzo gutanje i pomicanje velikih količina podataka zbog karakteristika i svojstava performansi koje pomažu u postizanju skalabilnosti, pouzdanosti i održivosti. U ovom smo članku raspravljali o Apache Kafki, njezinim značajkama, slučajevima uporabe i primjeni te što je čini boljim alatom za strujanje podataka.
Preporučeni članci
Ovo je vodič za Kafka aplikacije. Ovdje smo raspravljali o tome što je Kafka zajedno s vrhunskim Kafkinim aplikacijama koje uključuju široko primijenjene slučajeve uporabe i neke implementacije u stvarnom životu. Možete pogledati i sljedeće članke da biste saznali više -
- Što je Kafka?
- Kako instalirati Kafka?
- Kafka pitanja za intervju
- Apache Kafka vs Flume
- Top 8 uređaja IoT-a koje biste trebali znati
- Kafka vs Kinesis | Razlike s Infografikom
- Različite vrste alata Kafka s komponentama
- Saznajte najbolje razlike između ActiveMQ i Kafka