
Što je SVM algoritam?
SVM znači Stroj za podršku vektora. SVM je nadzirani algoritam strojnog učenja koji se obično koristi za izazove klasifikacije i regresije. Uobičajene primjene SVM algoritma su sustav za otkrivanje provale, prepoznavanje rukopisa, predviđanje strukture proteina, otkrivanje stenografije u digitalnim slikama itd.
U algoritmu SVM svaka je točka predstavljena kao podatkovna stavka unutar n-dimenzionalnog prostora gdje je vrijednost svake značajke vrijednost određene koordinate.
Nakon crtanja provodi se klasifikacija pronalaskom hiper-ravnine koja razlikuje dvije klase. Pogledajte sliku ispod kako biste razumjeli ovaj koncept.
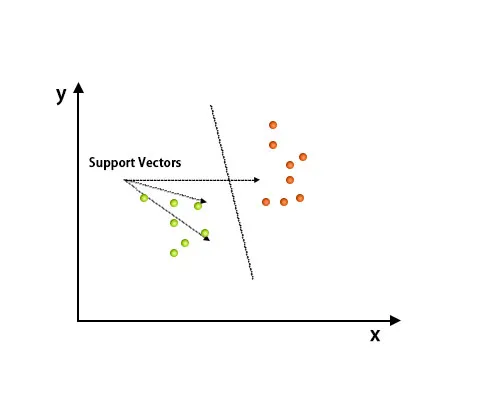
Algoritam vektora za podršku vektora uglavnom se koristi za rješavanje problema s klasifikacijom. Vektori podrške nisu samo koordinate svakog podatka. Vector Vector Machine je granica koja razlikuje dvije klase pomoću hiper-ravnine.
Kako funkcionira SVM algoritam?
U gornjem dijelu smo razgovarali o diferencijaciji dviju klasa pomoću hiper-ravnine. Sada ćemo vidjeti kako ovaj SVM algoritam zapravo funkcionira.
Scenarij 1: Prepoznavanje prave hiper-ravnine
Ovdje smo uzeli tri hiper-ravnine tj. A, B i C. Sada moramo identificirati pravu hiper-ravninu da bismo klasificirali zvijezdu i krug.
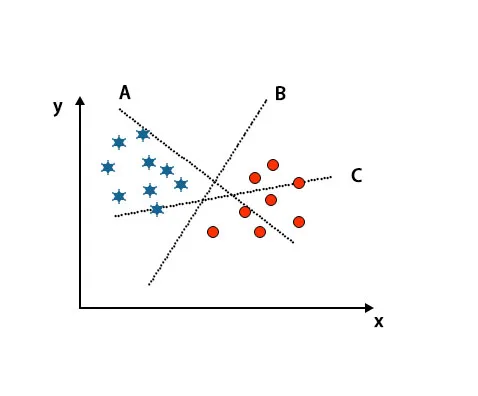
Za prepoznavanje prave hiper-ravnine trebali bismo znati pravilo palca. Odaberite hiper-ravninu koja razlikuje dvije klase. U gore spomenutoj slici, hiper-ravnina B vrlo dobro razlikuje dvije klase.
Scenarij 2: Prepoznavanje prave hiper-ravnine
Ovdje smo uzeli tri hiper-ravnine tj. A, B i C. Te tri hiper-ravnine već vrlo dobro razlikuju klase.
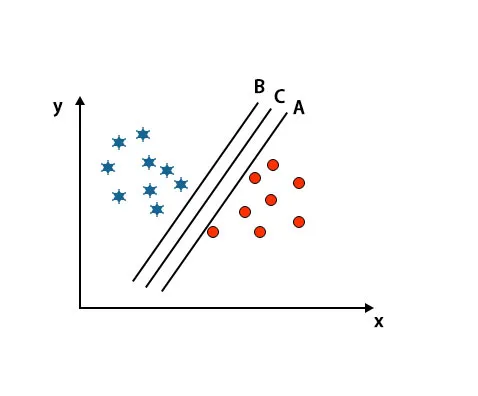
U ovom scenariju, za prepoznavanje prave hiper-ravnine povećavamo udaljenost između najbližih podataka. Ta udaljenost nije samo margina. Pogledajte ispod slike.
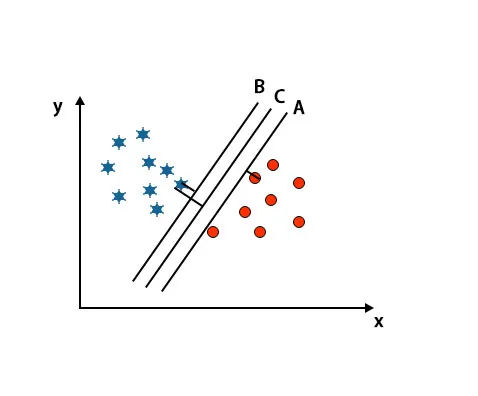
U gore spomenutoj slici granica hiper-ravnine C je veća od hiper-ravnine A i hiper-ravnine B. Dakle, u ovom scenariju, C je prava hiperplana. Ako odaberemo hiperplanu s minimalnom razinom, može dovesti do pogrešne klasifikacije. Stoga smo izabrali hiperplanu C s najvećom maržom zbog robusnosti.
Scenarij 3: Prepoznavanje prave hiper-ravnine
Napomena: Za prepoznavanje hiper-ravnine slijedite ista pravila kao što je spomenuto u prethodnim odjeljcima.
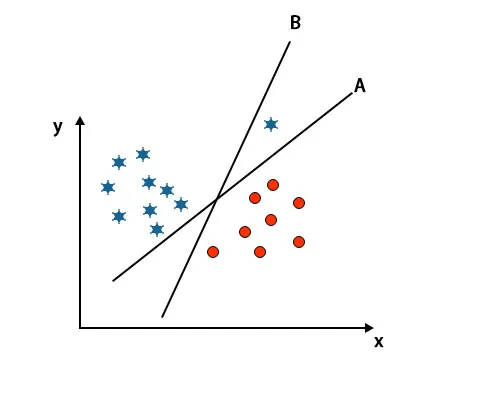
Kao što možete vidjeti na gore navedenoj slici, granica hiper-ravnine B veća je od granice hiper-ravnine A, zato će neki odabrati hiper-ravninu B kao pravu. Ali u SVM algoritmu, on odabire hiper-ravninu koja klasificira klase točne prije maksimiziranja marže. U ovom scenariju, hiper-ravnina A je klasificirala sve točno i postoji neka greška. S klasifikacijom hiper-ravnine B. Stoga je A prava hiper-ravnina.
Scenarij 4: Klasificirajte dvije klase
Kao što možete vidjeti na donjoj slici, ne možemo razlikovati dvije klase pomoću ravne linije jer jedna zvijezda leži kao izvanjska vrijednost u drugoj klasi kruga.
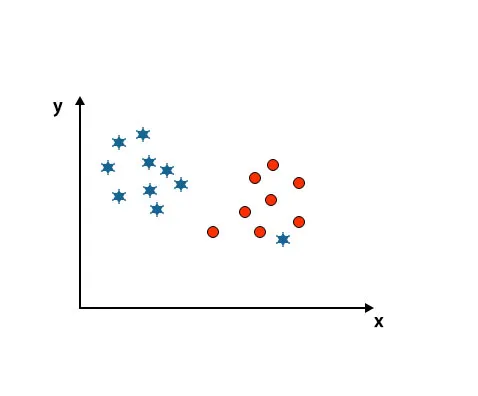
Ovdje je jedna zvijezda u drugoj klasi. Za zvjezdanu klasu ova je zvijezda vanserijska. Zbog svojstva robusnosti SVM algoritma, pronaći će pravu hiperplanu s višom marginom zanemarivanja vanjske vrijednosti.
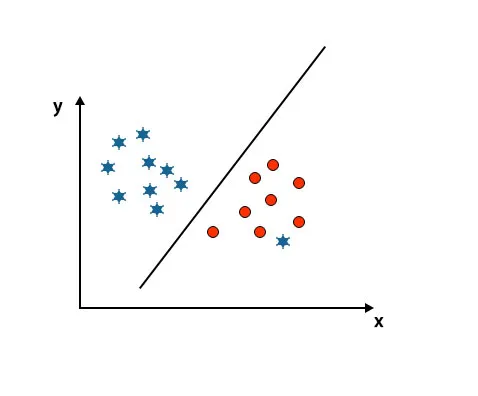
Scenarij 5: Fina hiper-ravnina za razlikovanje klasa
Do sad smo gledali linearnu hiper-ravninu. Na slici ispod, nemamo linearnu hiper-ravninu između klasa.
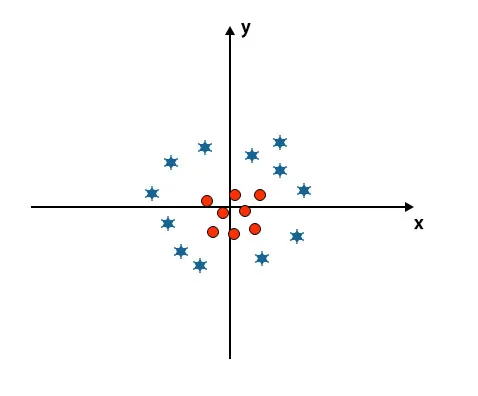
Za razvrstavanje ovih klasa SVM uvodi neke dodatne značajke. U ovom scenariju koristit ćemo ovu novu značajku z = x 2 + y 2.
Nacrtajte sve podatkovne točke na x i z-osi.

Bilješka
- Sve vrijednosti na z-osi trebaju biti pozitivne jer je z jednak zbroju x kvadrata i y kvadrata.
- Na gore spomenutom crtežu crveni su krugovi zatvoreni prema podrijetlu osi x i y, vodeći vrijednost z do niže, a zvijezda je upravo suprotna od kruga, udaljena je od podrijetla osi x i y-osi, vodeći vrijednost z do visoke.
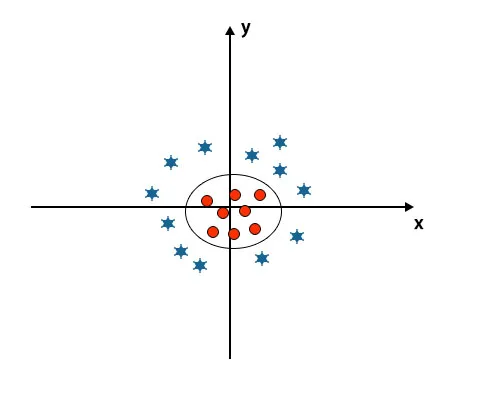
U SVM algoritmu lako je razvrstati linearnom hiperplanom između dvije klase. Ali ovdje se postavlja pitanje treba li dodati ovu značajku SVM-a za prepoznavanje hiper-ravnine. Dakle, odgovor je ne, za rješavanje ovog problema SVM ima tehniku koja je općenito poznata kao kernel trik.
Kernel trik je funkcija koja pretvara podatke u prikladan oblik. Postoje razne vrste kernel funkcija koje se koriste u SVM algoritmu, tj. Polinomna, linearna, nelinearna, radijalna osnova osnove itd. Ovdje se pomoću nisko-dimenzionalnog ulaznog prostora s trikom kernela pretvara u prostor višeg dimenzija.
Kad pogledamo hiperplane na podrijetlo osi i osi, izgleda kao krug. Pogledajte ispod slike.
Pros SVG algoritam
- Čak i ako su ulazni podaci nelinearni i ne razdvajajući, SVM generiraju točne rezultate klasifikacije zbog svoje robusnosti.
- U funkciji odlučivanja koristi podskup trening bodova koji se nazivaju potporni vektori, stoga je memorijski učinkovit.
- Bilo koji složen problem korisno je riješiti odgovarajućom funkcijom kernela.
- U praksi se SVM modeli generaliziraju, s manjim rizikom prekomjernog uklapanja u SVM.
- SVM izvrsno funkcioniraju za klasifikaciju teksta i za pronalaženje najboljeg linearnog separatora.
Slabosti SVM algoritma
- Pri radu s velikim nizovima podataka potrebno je dugo vremena obuke.
- Teško je razumjeti konačni model i pojedinačni utjecaj.
Zaključak
Vodi se za podršku algoritmu vektorskih strojeva koji je algoritam strojnog učenja. U ovom ćemo članku detaljno razgovarati o tome što je SVM algoritam, kako radi i koje su njegove prednosti.
Preporučeni članci
Ovo je vodič za SVM algoritam. Ovdje smo raspravljali o njegovom radu sa scenarijem, prednosti i nedostacima SVM algoritma. Možete pogledati i sljedeće članke da biste saznali više -
- Algoritmi vađenja podataka
- Tehnike vađenja podataka
- Što je strojno učenje?
- Alati za strojno učenje
- Primjeri C ++ algoritma