

Razlika između Apache Nifi iApache Spark
Sve do dugo vremena, kada je trebalo obaviti težak posao, ljudi su se oslanjali na konje kako bi povukli teške terete, održavali brzinu ili bilo što drugo između njih. Međutim, nisu svi konji bili prikladni za svaki zadatak. Isti je slučaj danas s tehnologijom. Pojavom novih tehnologija koje se svakodnevno ulivaju, postaje izuzetno važno znati njihovu stvarnu primjenu. Dvije takve tehnologije su Apache Nifi i Apache Spark i o njima ćemo proučavati u ovom postu.
Apache Spark je klasterski računski open source okvir koji ima za cilj pružiti sučelje za programiranje čitavog skupa klastera s implicitnom tolerancijom grešaka i paralelizmom podataka. Koristi RDD (Resilient Distributed skupove podataka) i obrađuje podatke u obliku diskretiziranih tokova koji se dalje koriste u analitičke svrhe.
Apache Nifi (što je kratki oblik NiagaraFilesa) je još jedan softverski projekt koji ima za cilj automatizirati protok podataka između softverskih sustava. Dizajn se temelji na modelu programiranja temeljenom na protoku koji pruža značajke koje uključuju rad s mogućnošću klastera. To je jednostavan za korištenje, pouzdan i moćan sustav za obradu i distribuciju podataka. Podržava skalabilne usmjerene grafikone za usmjeravanje podataka, posredovanje sustava i logiku transformacije. Raspravimo o usporedbama obje teme.
Usporedba između Apache Nifi i Apache Spark (Infographics)
Ispod je 9 najboljih usporedbi Apache Nifi sa Apache Sparkom
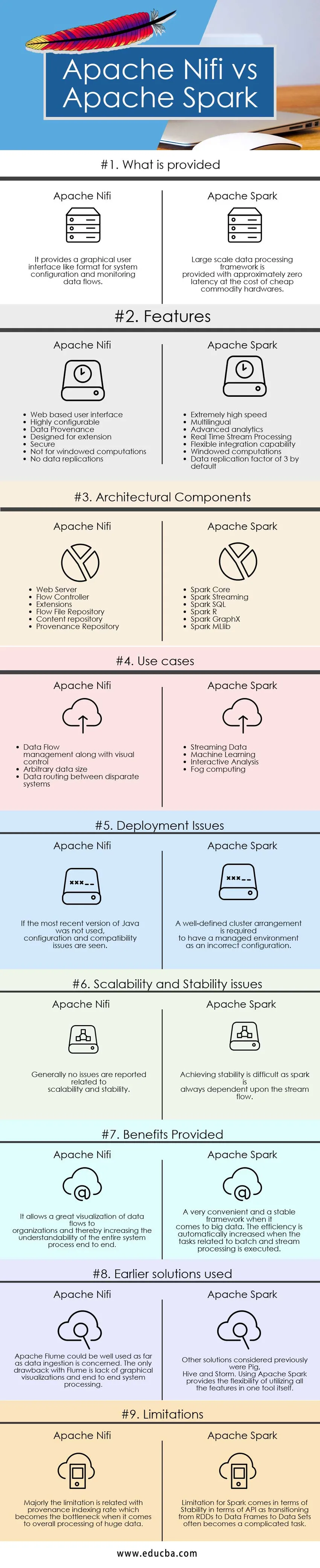
Ključne razlike između Apache Nifi i Apache Spark
Razlike između Apache Nifi i Apache Spark objašnjene su u donjim točkama:
- Apache Nifi je alat za unošenje podataka koji se koristi za pružanje jednostavnog, moćnog i pouzdanog sustava, tako da obrada i distribucija podataka preko resursa postaje jednostavna, dok je Apache Spark izuzetno brza računalna tehnologija klastera koja je dizajnirana za brže računanje pomoću učinkovito korištenje interaktivnih upita, u upravljanju memorijom i mogućnosti obrade protoka.
- Apache Nifi radi u samostalnom načinu rada i u klaster režimu, dok Apache Spark dobro funkcionira u lokalnom ili samostalnom načinu rada, Mesosu, Predi i drugim vrstama velikih podataka sa skupinama podataka.
- Značajke Apache Nifi uključuje zajamčenu isporuku podataka, učinkovito međusobno spremanje podataka, prioritetno postavljanje u redove, protok specifičan QoS, protokol podataka, oporavak valjkastog međuspremnika, vizualnu naredbu i kontrolu, predloške protoka, sigurnost, paralelno strujanje mogućnosti, dok značajke apache iskre uključuju munje brzo brzina obrade, višejezičnost, računanje u memoriji, učinkovito korištenje robnih hardverskih sustava, napredna analitika, efikasna sposobnost integracije.
- Apache Nifi omogućuje bolju čitljivost i cjelovito razumijevanje sustava pružanjem mogućnosti vizualizacije i značajki povlačenja i ispuštanja. Tijekom podataka lako se upravlja i upravlja uobičajenim tehnikama i procesima dok je u slučaju Apache Spark-a da biste vidjeli ove vrste vizualizacija potreban sustav upravljanja klasterima poput Ambarija. Apache Spark sam po sebi ne pruža mogućnosti vizualizacije i dobar je program što se programa tiče. Daleko je to vrlo zgodan i stabilan sustav za obradu ogromnih količina podataka.
- Ograničenje kod Apache Nifi povezano je s onim što je njegova prednost. Jedina značajka povlačenja i ispuštanja pruža ograničenje što ne može skalirati i pružiti robusnost kada je u pitanju integriranje s drugim komponentama i alatima, dok u slučaju Apache Spark primarno ograničenje dolazi uz uporabu opsežnog robnog hardvera i upravljanje njima postaje mučan zadatak s vremena na vrijeme. Drugo prijavljeno ograničenje dolazi sa svojim mogućnostima strujanja povezanim s Diskretiziranim streamom i Windowed ili batch streamom gdje transformacija RDD-a u Data Data Frame i skupove podataka ponekad uzrokuje nestabilnost.
Apache Nifi vs Apache Spark Tablica za usporedbu
| Osnove usporedbe | Apache Nifi | Apache Spark |
| Što se pruža | Pruža grafičko korisničko sučelje poput formata za konfiguraciju sustava i nadgledanje protoka podataka. | Okvir za obradu podataka velikih razmjera dostupan je s otprilike nultu kašnjenju po cijeni jeftinog robnog hardvera. |
| Značajke |
|
|
| Arhitektonske komponente |
|
|
| Koristite slučajeve |
|
|
| Pitanja o primjeni | Ako najnovija inačica Java nije korištena, vide se problemi s konfiguracijom i kompatibilnošću | Dobro definirani raspored klastera potreban je da bi se upravljalo okruženje kao netočna konfiguracija |
| Pitanja o skalabilnosti i stabilnosti | Općenito nisu zabilježena pitanja koja se odnose na skalabilnost i stabilnost | Postizanje stabilnosti je teško jer iskra uvijek ovisi o protoku struje. |
| Prednosti pružene | Omogućuje veliku vizualizaciju protoka podataka organizacijama i na taj način povećava razumljivost cijelog procesa do kraja | Vrlo povoljan i stabilan okvir kada su u pitanju veliki podaci. Učinkovitost se automatski povećava kada se izvršavaju zadaci koji se odnose na serijsku i strujnu obradu. |
| Ranija korištena rješenja | Apache Flume bi se mogao dobro upotrijebiti što se tiče gutanja podataka. Jedini nedostatak Flumea je nedostatak grafičkih vizualizacija i cjelovite obrade sustava | Ostala razmatrana rješenja bila su Pig, Panj i Oluja. Korištenje Apache Spark pruža fleksibilnost korištenja svih značajki u jednom alatu. |
| Ograničenja | Ograničenje je uglavnom povezano sa stopom indeksiranja porijekla koja postaje usko grlo kada je u pitanju cjelokupna obrada ogromnih podataka | Ograničenje za Spark dolazi u smislu stabilnosti u pogledu API-ja jer prelazak s RDD-a na okvire podataka u skupove podataka često postaje složen zadatak. |
Zaključak - Apache Nifi vs Apache Spark
Za zaključak posta, može se reći da je Apache Spark teški ratni konj dok je Apache Nifi brzi trkački konj. Oboje imaju svoje prednosti i ograničenja koja će se koristiti u njihovim područjima. Trebate odlučiti pravi alat za vaše poslovanje. Pratite naš blog za više članaka vezanih za novije tehnologije velikih podataka.
Preporučeni članak
Ovo je vodič za Apache Nifi vs Apache Spark, njihovo značenje, usporedbu između glave, ključne razlike, tablicu usporedbe i zaključak. Možete pogledati i sljedeće članke da biste saznali više -
- Apache Hadoop vs Apache Spark | Top 10 usporedbi koje morate znati!
- Apache Storm vs Apache Spark - Naučite 15 korisnih razlika
- 7 važnih stvari o Apache iskre (vodič)
- Najboljih 15 stvari koje morate znati o MapReduceu vs Spark