

Razlika između velikih podataka i Apache Hadoop
Sve je na Internetu. Internet ima puno podataka. Stoga je sve Big Data. Znate li da se 2, 5 Quintillion bytes podataka stvaraju svaki dan i gomilaju se kao Veliki podaci? Naše svakodnevne aktivnosti poput komentara, lajkova, objava itd. Na društvenim mrežama poput Facebooka, LinkedIna, Twittera i Instagrama zbrajaju se kao veliki podaci. Pretpostavlja se da će se do 2020. godine stvoriti gotovo 1, 7 megabajta podataka svake sekunde, za svaku osobu na zemlji. Možete zamisliti i razmotriti koliko se podataka generira pretpostavkom svake pojedine osobe na zemlji. Danas smo povezani i dijelimo svoje živote na mreži. Većina nas je povezana putem interneta. Živimo u pametnom domu i koristimo pametna vozila i svi su povezani s našim pametnim telefonima. Zamislite li ikad kako ti uređaji postaju pametni? Želim vam dati vrlo jednostavan odgovor, to je zbog analize vrlo velike količine podataka, tj. Big Data. U roku od pet godina u svijetu će postojati preko 50 milijardi pametno povezanih uređaja, svi razvijeni za prikupljanje, analizu i razmjenu podataka kako bi naš život bio ugodniji.
Slijedi Uvod velikih podataka protiv Apache Hadoopa
Uvođenje termina Big Data
Što su veliki podaci? Koja se veličina podataka smatra velikim i bit će nazvana velikim podacima? Imamo mnogo relativnih pretpostavki za pojam Big Data. Moguće je da se količina podataka, recimo 50 terabajta, može smatrati velikim podacima za Start-up, ali možda to nisu veliki podaci za tvrtke poput Googlea i Facebooka. To je zato što imaju infrastrukturu za pohranjivanje i obradu te količine podataka. Želio bih definirati pojam Veliki podaci kao:
- Veliki podaci su količina podataka koja je veća od mogućnosti tehnologije za učinkovito pohranjivanje, upravljanje i obradu.
- Veliki podaci su podaci čija razmjera, raznolikost i složenost zahtijevaju novu arhitekturu, tehnike, algoritme i analitiku da bi se njima upravljalo i iz njega se izvlačilo vrijednost i skriveno znanje.
- Veliki podaci su sredstva velike brzine i velike brzine i velike raznolikosti, koja zahtijevaju ekonomične, inovativne oblike obrade podataka koji omogućavaju poboljšani uvid, odlučivanje i automatizaciju procesa.
- Big Data odnosi se na tehnologije i inicijative koje uključuju previše raznolike, brzo mijenjajuće se ili masovne da bi se konvencionalne tehnologije, vještine i infrastruktura mogli učinkovito baviti. Rečeno različito, volumen, brzina ili raznolikost podataka prevelika je.
3 V od velikih podataka
- Količina: Količina se odnosi na količinu / količinu kojom se podaci stvaraju kao na svakih sat vremena, Wal-Mart-ove transakcije pružaju kompaniji oko 2, 5 petabajta podataka.
- Velocity: Velocity se odnosi na brzinu kojom se podaci kreću kao da korisnici Facebooka u prosjeku šalju 31, 25 milijuna poruka i svakog dana pregledavaju 2, 77 milijuna video zapisa svakog minuta.
- Raznolikost: Raznolikost se odnosi na različite formate podataka koji se stvaraju poput strukturiranih, polustrukturiranih i nestrukturiranih podataka. Kao i slanje e-poruka s prilogom na Gmailu je nestrukturirani podaci, dok objavljivanje komentara s nekim vanjskim vezama također se naziva nestrukturiranim podacima. Dijeljenje slika, audio zapisa i video zapisa nestrukturiran je oblik podataka.
Veliki problem je pohranjivanje i obrada ove ogromne količine, brzine i raznolikosti podataka. Moramo razmišljati o drugoj tehnologiji osim RDBMS-a za velike podatke. To je zato što je RDBMS sposoban za pohranu i obradu samo strukturiranih podataka. Dakle, ovdje Apache Hadoop dolazi kao spas.
Predstavljamo pojam Apache Hadoop
Apache Hadoop je softver otvorenog koda za spremanje podataka i pokretanje aplikacija na klasterima robnog hardvera. Apache Hadoop je softverski okvir koji omogućava distribuiranu obradu velikih skupova podataka preko klastera računala koristeći jednostavne modele programiranja. Dizajniran je tako da se poveća s jednog poslužitelja na tisuće strojeva, a svaki od njih nudi lokalno računanje i pohranu. Apache Hadoop je okvir za pohranu i obradu velikih podataka. Apache Hadoop je u stanju pohraniti i obraditi sve formate podataka poput strukturiranih, polustrukturiranih i nestrukturiranih podataka. Apache Hadoop je open source i robni hardver donio revoluciju IT industriji. Lako je dostupan na svim razinama tvrtki. Ne moraju ulagati više u osnivanje Hadoop klastera i u drugu infrastrukturu. Tako ćemo detaljno vidjeti korisnu razliku između Big Data-a i Apache Hadoop-a u ovom postu.
Okvir Apache Hadoop
Okvir Apache Hadoop podijeljen je u dva dijela:
- Hadoop distribuirani datotečni sustav (HDFS): Ovaj sloj odgovoran je za pohranu podataka.
- MapReduce: Ovaj sloj odgovoran je za obradu podataka na Hadoop Cluster-u.
Hadoop Framework je podijeljen na glavnu i slavensku arhitekturu. Sloj Hadoop Distribuiranog datotečnog sustava (HDFS) Naziv je čvor glavna komponenta dok je Data čvor Slave komponenta dok je u sloju MapReduce Job Tracker glavna komponenta dok je tracker zadataka slave komponenta. Ispod je dijagram za Apache Hadoop okvir.
Zašto je Apache Hadoop važan?
- Sposobnost brzog pohranjivanja i obrade ogromne količine bilo koje vrste podataka
- Računalna snaga: Hadoopov model raspodjele računala brzo obradjuje velike podatke. Što više računskih čvorova koristite, to imate veću moć obrade.
- Tolerancija pogreške: Obrada podataka i aplikacija zaštićena je od kvara hardvera. Ako čvor propadne, poslovi se automatski preusmjeravaju na druge čvorove kako bi se osiguralo da distribuirano računanje ne uspije. Višestruke kopije svih podataka automatski se pohranjuju.
- Fleksibilnost: Možete pohraniti koliko želite podataka i odlučiti kako ih kasnije koristiti. To uključuje nestrukturirane podatke poput teksta, slika i videozapisa.
- Niski troškovi: Okvir otvorenog koda je besplatan i koristi ročni hardver za pohranu velikih količina podataka.
- Skalabilnost: Sustav možete lako rasti kako biste obrađivali više podataka jednostavnim dodavanjem čvorova. Potrebno je malo uprave
Usporedba između velikih podataka i Apache Hadoop (Infographics)
Ispod je najbolja 4 usporedba podataka Big Data vs Apache Hadoop
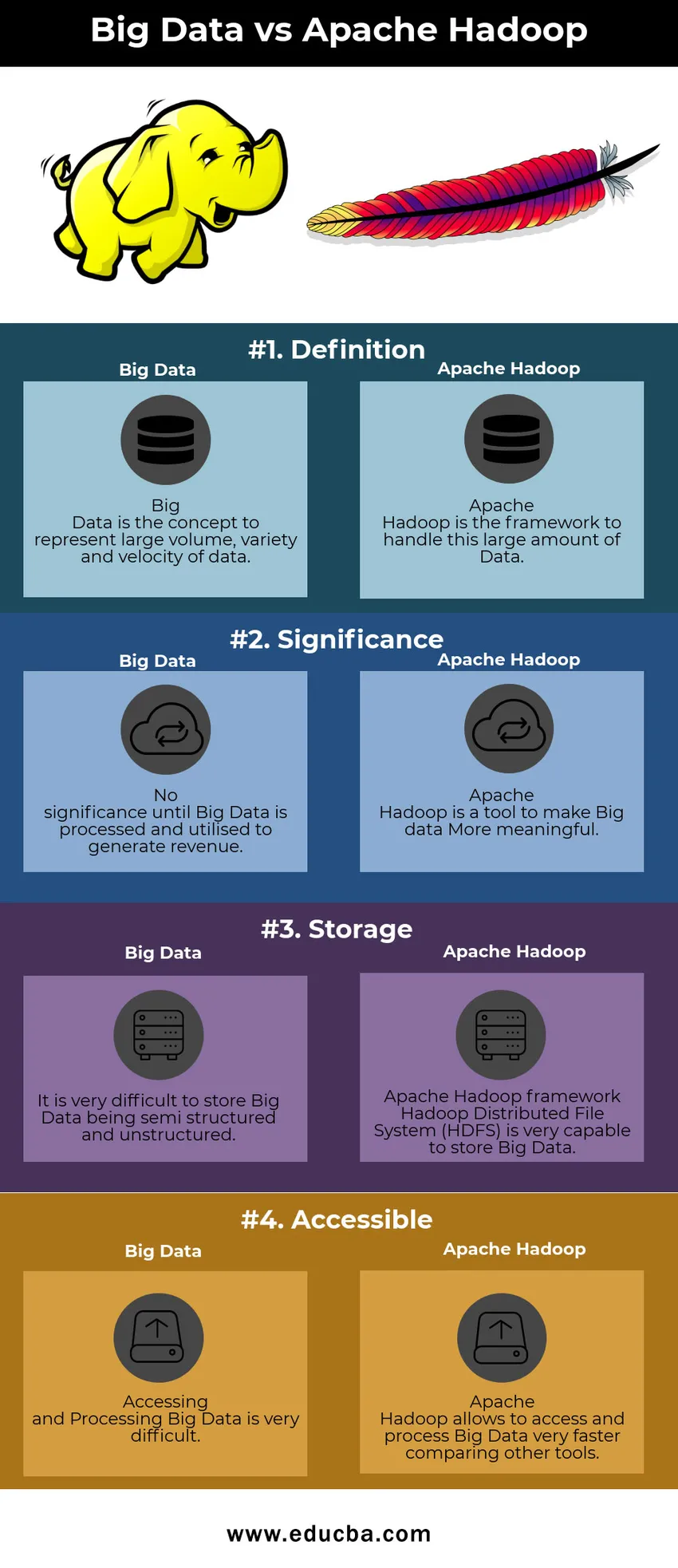
Tabela usporedbe velikih podataka vs Apache Hadoop
Raspravljam o glavnim artefaktima i razlikujem Big Data od Apache Hadoopa
| Veliki podaci | Apache Hadoop | |
| definicija | Big Data je koncept koji predstavlja veliku količinu, raznolikost i brzinu podataka | Apache Hadoop je okvir za obradu ove velike količine podataka |
| Značaj | Nema značaja dok se Veliki podaci ne obrade i ne iskoriste za stvaranje prihoda | Apache Hadoop je alat za stvaranje značajnijih podataka |
| skladištenje | Vrlo je teško pohraniti Big Data koji su polustrukturirani i nestrukturirani | Okvir Apache Hadoop Hadoop distribuirani datotečni sustav (HDFS) vrlo je sposoban za pohranu velikih podataka |
| dostupan | Pristup i obrada velikih podataka vrlo je teška | Apache Hadoop omogućuje pristup i obradu Big Data-a vrlo bržim usporedbom s drugim alatima |
Zaključak - Big Data vs Apache Hadoop
Ne možete usporediti Big Data i Apache Hadoop. Razlog je to što je Big Data problem dok je Apache Hadoop rješenje. Budući da se količina podataka eksponencijalno povećava u svim sektorima, stoga je vrlo teško pohraniti i obraditi podatke iz jedinstvenog sustava. Da bismo obradili ovu veliku količinu podataka, potrebna nam je distribuirana obrada i pohrana podataka. Stoga Apache Hadoop nudi rješenje za pohranu i obradu vrlo velike količine podataka. Za kraj ću zaključiti da je Big Data velika količina složenih podataka, dok je Apache Hadoop mehanizam za pohranu i obradu Big Data-a vrlo učinkovito i glatko.
Preporučeni članak
Ovo je vodič za velike podatke u odnosu na Apache Hadoop, njihovo značenje, usporedbu između glave, ključne razlike, tablicu usporedbe i zaključak. ovaj se članak sastoji od svih korisnih razlika između Big Data-a i Apache Hadoop-a. Možete pogledati i sljedeće članke da biste saznali više -
- Veliki podaci u odnosu na znanost podataka - u čemu se razlikuju?
- Top 5 trendova velikih podataka koje će tvrtke morati savladati
- Hadoop vs Apache Spark - Zanimljive stvari koje trebate znati
- Apache Hadoop vs Apache Spark | Top 10 usporedbi koje morate znati!