

Razlika između MapReduce i Spark
Map Reduce je open-source okvir za pisanje podataka u HDFS i obradu strukturiranih i nestrukturiranih podataka prisutnih u HDFS. Smanjivanje karte ograničeno je na serijsku obradu, a na ostalim je Spark sposoban raditi bilo koju vrstu obrade. SPARK je neovisni procesor za obradu u stvarnom vremenu koji se može instalirati na bilo koji distribuirani datotečni sustav kao što je Hadoop. SPARK pruža performanse koje su 10 puta brže od smanjivanja karata na disku i 100 puta brže od smanjenja mapa na mreži u memoriji.
Need for SPARK
- Iterative Analytics: Smanjivanje karte nije tako učinkovito kao SPARK za rješavanje problema koji zahtijevaju iterativnu analitiku jer mora ići na disk za svaku iteraciju.
- Interaktivna analitika: Smanjivanje karte često se koristi za pokretanje ad-hoc upita za koje treba doći do diskovne memorije koja opet nije tako učinkovita kao SPARK jer se potonja odnosi u bržu memoriju.
- Nije pogodno za OLTP: Kako djeluje na batch orijentirani okvir, nije pogodan za veliki broj kratkih transakcija.
- Nije pogodno za graf: Biblioteka Apache Graph obrađuje graf što dodaje složenost smanjenju karata.
- Nije pogodno za trivijalne operacije: Za operacije poput filtra i spajanja možda ćemo trebati prepisati zadatke, što postaje složenije zbog obrasca ključ-vrijednost.
Usporedba između MapReduce i Spark (Infographics)
Ispod je top 15 razlike između MapReduce i Spark

Ključne razlike između MapReduce i Spark
Ispod su popisi točaka, opišite ključne razlike između MapReduce i Spark:
- Spark je prikladan u realnom vremenu dok se koristi pomoću memorije dok je MapReduce ograničen na skupnu obradu.
- Spark ima RDD (Resilient Distributed Dataset) koji nam daje operatore visoke razine, ali u Map smanjiti moramo kodirati svaku operaciju što je čini komparativnom.
- Spark može obraditi grafikone i podržava alat Strojno učenje.
- Ispod je razlika između ekosustava MapReduce i Spark.
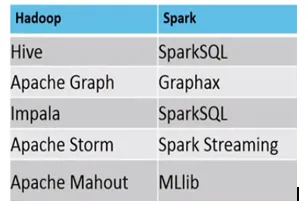
Primjer, gdje je MapReduce vs Spark prikladan, je sljedeći
Iskra: Otkrivanje prevare s kreditnom karticom
MapReduce: Izrada redovitih izvještaja koja zahtijevaju donošenje odluka.
Tablica za usporedbu MapReduce vs iskre
| Osnove usporedbe | MapReduce | Iskra |
| Okvir | Okvir otvorenog koda za pisanje podataka u HDFS i obradu strukturiranih i nestrukturiranih podataka prisutnih u HDFS. | Okvir otvorenog koda za bržu i opću obradu podataka |
| Ubrzati | Mapiranje smanjuje obradu podataka (čitanje i pisanje) s diska tako da je prodiranje sporo u usporedbi sa Sparkom. | Spark je barem 10X brži na disku i 100X brži u memoriji kao i Map Map Reduce. |
| teškoća | Moramo kodirati / obraditi svaki postupak. | S dostupnošću RDD (Resilient Distributed Dataset) jednostavno je programirati. |
| Stvarno vrijeme | Nije pogodno za OLTP transakciju samo za batch način rada | Može podnijeti obradu u stvarnom vremenu. Upotreba SPARK Streaminga. |
| Latentnost | Računalni okvir za kašnjenje na visokoj razini | Računalni okvir latencije na niskoj razini. |
| Tolerancija kvarova | Glavni demoni provjeravaju otkucaje demona robova i u slučaju da demoni robova ne uspiju, master demoni prebaciti sve na čekanju i u tijeku s radom na drugi rob. | RDD-ovi osiguravaju toleranciju greške SPARK-u. Oni se odnose na skup podataka koji se nalazi u vanjskoj pohrani kao (HDFS, HBase) i djeluje paralelno. |
| raspored | U Map Reduci koristimo vanjski planer poput Oozie. | Dok SPARK radi s računanjem u memoriji, on djeluje kao vlastiti planer. |
| cijena | Smanjenje karte je relativno jeftinije u usporedbi sa SPARK-om. | Kao što djeluje u memoriji, tako mu treba i puno RAM-a što ga čini relativno skupljim. |
| Platforma razvijena na | Smanjivanje karte razvijeno je pomoću Java. | SPARK je razvijen pomoću Scale. |
| Podržani jezik | Map Reduct u osnovi podržava C, C ++, Ruby, Groovy, Perl, Python. | Spark podržava Scala, Java, Python, R, SQL. |
| SQL podrška | Map Reduct pokreće upite pomoću jezika upita košnice. | Spark ima svoj jezik upita poznat kao Spark SQL. |
| skalabilnost | U Reduciranje karata možemo dodati do n broja čvorova. Najveći Hadoop klaster ima 14000 čvorova. | U Spark također možemo dodati n broj čvorova. Najveći Spark cluster ima 8000 čvorova. |
| Strojno učenje | Map Reduce podržava Apache Mahout alat za strojno učenje. | Spark podržava MLlib alat za strojno učenje. |
| caching | Map smanjenje ne može predmemorirati memorijske podatke, tako da nije tako brzo u usporedbi sa Sparkom. | Spark sprema memorijske podatke za daljnje iteracije tako da je vrlo brz u usporedbi sa Smanjivanjem karte. |
| sigurnosti | Map Reduce podržava više sigurnosnih projekata i značajki u odnosu na Spark | Sigurnost iskre još uvijek nije sazrela kao zaštita karte |
Zaključak - MapReduce vs Spark
Prema gornjoj razlici između MapReduce i Spark-a, prilično je jasno da je SPARK mnogo napredniji računalni motor u usporedbi s redukcijom karata. Spark je kompatibilan s bilo kojom vrstom datoteke, a također je prilično brži od smanjivanja mapa. Iskra ujedno ima i mogućnosti obrade grafikona i mogućnosti strojnog učenja.
S jedne strane, smanjenje karte je ograničeno na grupnu obradu, a s druge je Spark sposoban raditi bilo koju vrstu obrade (skupna, interaktivna, iterativna, strujna, grafička). Zbog velike kompatibilnosti, Spark je omiljen za Data Scientist, pa je zbog toga njegova zamjena Karte smanjila i brzo rasla. Ipak, moramo pohraniti podatke u HDFS, a ponekad nam može trebati i HBase. Zato moramo pokrenuti i Spark i Hadoop da bismo postigli najbolje.
Preporučeni članci:
Ovo je bio vodič za MapReduce vs Spark, njihovo značenje, usporedba "Head to Head", ključne razlike, tablica usporedbe i zaključak. Možete pogledati i sljedeće članke da biste saznali više -
- 7 važnih stvari o Apache iskre (vodič)
- Hadoop vs Apache Spark - Zanimljive stvari koje trebate znati
- Apache Hadoop vs Apache Spark | Top 10 usporedbi koje morate znati!
- Kako MapReduce funkcionira?
- Konfucija tehnologije i poslovne analitike