

Uvod u iskrenje naredbe
Apache Spark je okvir izgrađen na vrhu Hadoopa za brza računanja. To proširuje koncept MapReduce u scenariju temeljenom na klasterima kako bi učinkovito izvršavao zadatak. Spark Command je napisan u Scali.
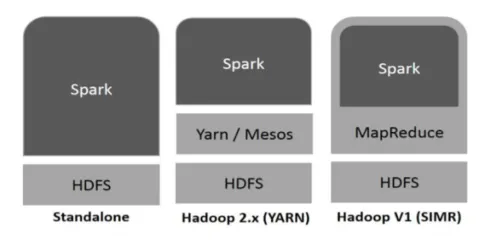
Hadoop Spark može koristiti na sljedeće načine (vidi dolje):
Sl. 1
https://www.tutorialspoint.com/
- Samostalan: Iskra se izravno postavlja na vrhu Hadoopa. Poslovi iskre se pokreću paralelno na Hadoop i Spark.
- Hadoop PRIJEV: Iskrica se pokreće na pređi bez ikakve predinstalacije.
- Iskra u MapReduce (SIMR): Iskra u MapReduceu koristi se za pokretanje iskričavanja, osim samostalne implementacije. Pomoću SIMR-a, Spark može pokrenuti Spark i može koristiti njegovu ljusku bez administrativnog pristupa.
Dijelovi iskre:
- Apache Spark Core
- Spark SQL
- Streaming iskre
- MLib
- GraphX
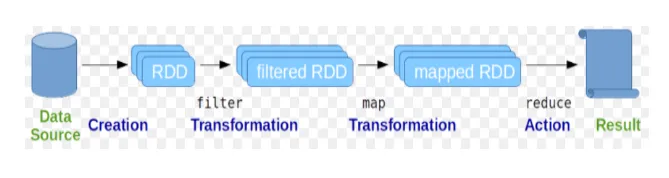
Elastični distribuirani skupovi podataka (RDD) smatraju se temeljnom strukturom podataka Spark naredbi. RDD je nepromjenljiv u prirodi i samo za čitanje. Sve vrste izračuna u naredbama iskra provode se kroz transformacije i akcije na RDD-ovima.
Slika 2
Google slika
Iskrica ljuske pruža medij za interakciju korisnika s njenim funkcionalnostima. Naredbe iskre imaju puno različitih naredbi koje se mogu koristiti za obradu podataka na interaktivnoj ljusci.
Osnovne iskra naredbe
Pogledajmo neke od osnovnih Spark naredbi koje su date u nastavku: -
-
Da biste pokrenuli ljusku iskre:

Slika 3
-
Čitanje datoteke iz lokalnog sustava:

Ovdje je "sc" kontekst iskre. S obzirom da se "data.txt" nalazi u kućnom imeniku, čita se ovako, a drugi trebate odrediti cijeli put.
-
Stvorite RDD paralelizacijom

NewData je sada RDD.
-
Prebrojite stavke u RDD-u

-
Prikupiti
Ova funkcija vraća sav RDD sadržaj upravljačkom programu. To je korisno kod uklanjanja pogrešaka u raznim koracima programa pisanja.
-
Pročitajte prve 3 stavke iz RDD-a

-
Spremite izlazne / obrađene podatke u tekstualnu datoteku

Ovdje je trenutna putanja "output" mape.
Posredničke iskra naredbe
1. Filtrirajte na RDD
Napravimo novi RDD za stavke koje sadrže "da".

Transformacijski filtar treba pozvati na postojeći RDD da bi se filtrirao riječju "da", što će stvoriti novi RDD s novim popisom stavki.
2. lanac rad

Ovdje su transformacija filtra i brojanje djelovanja djelovali zajedno. To se naziva lančana operacija.
3. Pročitajte prvu stavku iz RDD-a

4. Prebrojite RDD particije
Kao što znamo, RDD je izrađen od više particija, javlja se potreba za brojenjem ne. od pregrada. Kao što pomaže u podešavanju i rješavanju problema tijekom rada sa Spark naredbama.

Prema zadanim postavkama minimalni br. pf particija je 2.
5. pridružiti se
Ova funkcija povezuje dvije tablice (element tablice je u parovima) na temelju zajedničkog ključa. U parnom RDD-u, prvi je element ključni, a drugi element vrijednost.
6. Predmemorirajte datoteku
Predavanje je tehnika optimizacije. Keširanje RDD znači da će RDD ostati u memoriji, a sva buduća izračunavanja bit će izvršena na tim RDD-ima u memoriji. To štedi vrijeme za čitanje diska i poboljšava performanse. Ukratko, smanjuje se vrijeme pristupa podacima.

Međutim, podaci se neće predmemorirati ako pokrenete iznad funkcije. To se može dokazati posjetom web stranici:
http: // localhost: 4040 / skladišta
RDD će se spremiti u predmemoriju, nakon što je akcija izvršena. Na primjer:

Još jedna funkcija koja djeluje slično kao cache () je uporno (). Persist pruža korisnicima fleksibilnost u argumentaciji, što može pomoći podacima u predmemoriranju u memoriji, disku ili nepropusnoj memoriji. Ustraje bez ikakvih argumenata djeluje isto kao i cache ().
Napredne naredbe iskre
Pogledajmo neke napredne Spark naredbe koje su dane u nastavku: -
-
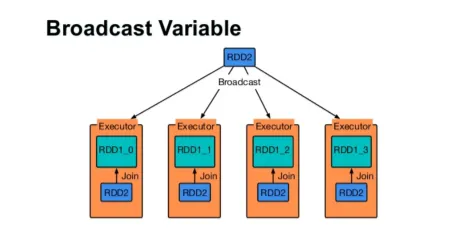
Prijenos varijable
Promjena emitiranja pomaže programeru da čita jedinu varijablu spremljenu u predmemorijsku mrežu na svakom stroju u klasteru, a ne otprema kopiju te varijable sa zadacima. To pomaže u smanjenju troškova komunikacije.
Slika 4
Google slika
Ukratko, postoje tri glavne karakteristike emitirane varijable:
- nepromjenljiv
- Uklapa se u memoriju
- Distribuira se po klasteru
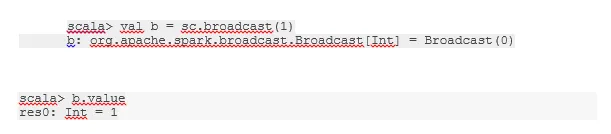
-
akumulatori
Akumulatori su varijable koje se dodaju povezanim operacijama. Mnogo je koristi za akumulatore poput brojača, zbroja itd.

Ime akumulatora u kodu moglo se vidjeti i u Spark UI.
-
Karta
Funkcija karte pomaže u iteriranju preko svakog retka u RDD-u. Funkcija koja se koristi u mapi primjenjuje se na svaki element u RDD-u.
Na primjer, u RDD (1, 2, 3, 4, 6) ako primijenimo "rdd.map (x => x + 2)", dobit ćemo rezultat kao (3, 4, 5, 6, 8).
-
Flatmap
Flatmap djeluje slično kao na mapi, ali karta vraća samo jedan element dok ravna karta može vratiti popis elemenata. Stoga će za podjelu rečenica u riječi trebati jasan prikaz.
-
srasti
Ova funkcija pomaže u izbjegavanju miješanja podataka. To se primjenjuje u postojećoj particiji tako da se manje podataka izmjenjuje. Na taj način možemo ograničiti upotrebu čvorova u klasteru.
Savjeti i trikovi za korištenje iskrećih naredbi
Ispod su sljedeći savjeti i trikovi Spark naredbi: -
- Početnici iskre mogu koristiti Spark-shell. Kako su Spark naredbe izgrađene na Scali, tako je i definitivno korištenje ljuske iskre shell sjajno. Međutim, dostupna je i svjećica python, tako da čak i to što netko može upotrijebiti, koji su dobro poznati s pitonom.
- Spark shell ima puno opcija za upravljanje resursima klastera. Ispod vam naredba može pomoći:

- U Sparku je rad s dugim skupovima podataka uobičajena stvar. No, stvari idu po zlu kada se uzimaju loši ulozi. Uvijek je dobra ideja ispustiti loše redove pomoću filtrirajuće funkcije Spark. Dobar unos će biti sjajan potez.
- Spark za svoje podatke odabire dobru particiju. No, uvijek je dobra praksa da pazite na particije prije nego što započnete svoj posao. Isprobavanje različitih particija pomoći će vam u paralelizmu vašeg posla.
Zaključak - Iskrene naredbe:
Spark naredba je revolucionarni i svestrani mehanizam za velike podatke, koji može raditi za grupnu obradu, real-time obradu, predmemoriranje podataka itd. Spark ima bogat skup strojnih učenja knjižnica koje mogu omogućiti znanstvenicima podataka i analitičkim organizacijama da izrade snažne, interaktivne i brze aplikacije.
Preporučeni članci
Ovo je vodič za Spark naredbe. Ovdje smo razgovarali o osnovnim, kao i naprednim Spark naredbama i nekim neposrednim Spark naredbama. Možete pogledati i sljedeći članak da biste saznali više -
- Naredbe Adobe Photoshop
- Važne VBA naredbe
- Tableau naredbe
- SQL šifre (naredbe, besplatni savjeti i trikovi)
- Vrste pridruživanja u Spark SQL-u (primjeri)
- Komponente iskre | Pregled i prvih 6 komponenti