
Definicija algoritma srednjeg pomaka
Algoritam srednjeg pomaka potpada pod nekontrolirano učenje koje je kategorizirano kao algoritam klasteriranja. Ideologija algoritma Srednji pomak je da iterativno dodjeljuje podatkovne točke klasterima pomicanjem prema tački koja ima točku najveće gustoće (Način). Srednja logika pomaka u osnovi temelji se na konceptu procjene gustoće kernela koji se naziva KDE.
Srednja klasterizacija algoritma pomaka
Nenadzirana tehnika učenja koju su Fukunaga i Hostetler otkrili kako bi pronašli klastere:
- Srednji pomak poznat je i kao algoritam traženja načina koji dodjeljuje podatkovne točke klasterima na način da preusmjerava podatkovne točke prema području visoke gustoće. Najveća gustoća podatkovnih točaka nazvana je kao model u regiji. Algoritam Mean Shift ima aplikacije koje se široko koriste u području računalnog vida i segmentacije slike.
- KDE je metoda za procjenu raspodjele podataka. Djeluje postavljanjem kernela na svaku točku podataka. Kernel u matematici je funkcija ponderiranja koja će primjenjivati utege za pojedine podatkovne točke. Dodavanje svih pojedinih kernela stvara vjerojatnost.
Kernel funkcija mora ispunjavati sljedeće uvjete:
- Prvi zahtjev je osigurati da se procjena gustoće kernela normalizira.
- Drugi je zahtjev da se KDE dobro povezuje sa simetrijom prostora.
Dvije popularne funkcije kernela
Ispod su korištene dvije popularne funkcije kernela:
- Ravna jezgra
- Gaussian Kernel
- Na temelju korištene Kernel parame, rezultirajuća funkcija gustoće varira. Ako se ne spominje nijedan parametar kernela, podrazumijeva se Gaussian Kernel. KDE koristi koncept funkcije gustoće vjerojatnosti koja pomaže pronaći lokalne maksimume distribucije podataka. Algoritam radi tako što podatkovne točke privlače jedna drugu te tako omogućuju podatkovne točke prema području velike gustoće.
- Točke podataka koje se pokušavaju približiti lokalnim maksimumima bit će iste skupine klastera. Za razliku od algoritma grupiranja K-Means, izlaz algoritma Srednje pomicanje ne ovisi o pretpostavkama o obliku podatkovne točke i broju klastera. Broj klastera određivat će se algoritamom u odnosu na podatke.
- Kako bismo izveli implementaciju algoritma Srednje pomicanje, koristimo python paket SKlearn.
Primjena algoritma Srednje pomake
Slijedi implementacija algoritma:
Primjer 1
Na temelju Sklearn Tutorial za srednji algoritam promjene klastera. Prvi isječak implementirat će srednji algoritam pomaka kako bi pronašao klastere dvodimenzionalnog skupa podataka. Paketi koji se koriste za primjenu algoritma srednjeg pomaka.
Kodirati:
fromcluster importMeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs as mb
importpyplot as plt
fromitertools import cycle as cy
Jedna ključna stvar koju treba napomenuti je da ćemo koristiti sklearnovu biblioteku make_blobs za generiranje podataka točaka usredotočenih na 3 lokacije. Da bismo primijenili algoritam Srednjeg pomaka na generirane točke, moramo postaviti širinu pojasa koja predstavlja interakciju između duljine. Sklearnova knjižnica ima ugrađene funkcije za procjenu propusnosti.
Kodirati:
#Sample data points
cen = ((1, .75), (-.75, -1), (1, -1)) x_train, _ = mb(n_samples=10000, centers= cen, cluster_std=0.6)
# Bandwidth estimation using in-built function
est_bandwidth = estimate_bandwidth(x_train, quantile=.1,
n_samples=500)
mean_shift = MeanShift(bandwidth= est_bandwidth, bin_seeding=True)
fit(x_train)
ms_labels = mean_shift.labels_
c_centers = ms_labels.cluster_centers_
n_clusters_ = ms_labels.max()+1
# Plot result
figure(1)
clf()
colors = cy('bgrcmykbgrcmykbgrcmykbgrcmyk')
fori, each inzip(range(n_clusters_), colors):
my_members = labels == i
cluster_center = c_centers(k) plot(x_train(my_members, 0), x_train(my_members, 1), each + '.')
plot(cluster_center(0), cluster_center(1),
'o', markerfacecolor=each,
markeredgecolor='k', markersize=14)
title('Estimated cluster numbers: %d'% n_clusters_)
show()
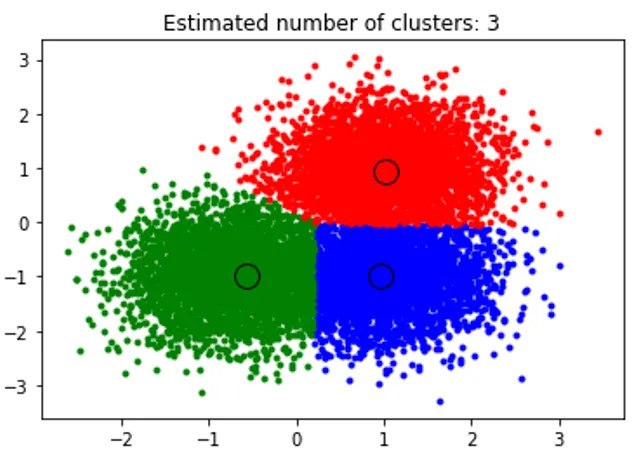
Gornji isječak izvodi klasteriranje, a algoritam je pronašao klastere u središtu svakog bloba koji smo generirali. Vidimo da na slici ispod prikazanoj isječkom prikazuje algoritam Srednjeg pomaka koji može identificirati broj klastera potrebnih u vremenu rada i utvrditi odgovarajuću širinu pojasa koji će predstaviti dužinu interakcije.
Izlaz:
Primjer 2
Na temelju segmentacije slike u računalnom vidu. Drugi isječak istražit će kako se algoritam Srednjeg pomaka koristi u Deep Learningu za izvođenje segmentacije obojene slike. Koristimo algoritam Srednje pomicanje da bismo identificirali prostorne klastere. Raniji isječak upotrijebio je dvodimenzionalni skup podataka dok će u ovom primjeru istražiti 3-D prostor. Piksel slike tretirat će se kao podatkovne točke (r, g, b). Moramo pretvoriti sliku u format matrice tako da svaki piksel predstavlja podatkovnu točku na slici koju idemo na segment. Klasteriranje vrijednosti boja u prostoru vraća niz klastera, pri čemu će pikseli u klasteru biti slični RGB prostoru. Paketi koji se koriste za implementaciju algoritma Srednje pomake:
Kodirati:
importnumpy as np
fromcluster importMeanShift, estimate_bandwidth
fromdatasets.samples_generator importmake_blobs
importpyplot as plt
fromitertools import cycle
fromPIL import Image
Ispod Isječka za izvođenje segmentacije Izvorne slike:
#Segmentation of Color Image
img = Image.open('Sample.jpg.webp')
img = np.array(img)
#Need to convert image into feature array based
flatten_img=np.reshape(img, (-1, 3))
#bandwidth estimation
est_bandwidth = estimate_bandwidth(flatten_img,
quantile=.2, n_samples=500)
mean_shift = MeanShift(est_bandwidth, bin_seeding=True)
fit(flatten_img)
labels= mean_shift.labels_
# Plot image vs segmented image
figure(2)
subplot(1, 1, 1)
imshow(img)
axis('off')
subplot(1, 1, 2)
imshow(np.reshape(labels, (854, 1224)))
axis('off')
Stvorena slika navodi da se ovaj pristup prepoznavanju oblika slike i određivanju prostornih klastera može učinkovito izvesti bez ikakve obrade slike.
Izlaz:


Prednosti i primjene znače algoritam pomaka
Ispod su prednosti i primjena srednjeg algoritma:
- Široko se koristi za rješavanje računalnog vida, gdje se koristi za segmentaciju slike.
- Klasteriranje podataka u stvarnom vremenu bez spominjanja broja klastera.
- Odlično djeluje na segmentaciju slike i praćenje videozapisa.
- Snažniji za odmetnike.
Profesionalni algoritam prosječnog pomaka
Ispod je algoritam pomaka u značenju pro:
- Izlaz algoritma ne ovisi o inicijalizaciji.
- Postupak je učinkovit jer ima samo jedan parametar - širinu pojasa.
- Nema pretpostavki o broju klastera podataka i obliku.
- Ima bolje performanse od K-Means Clustering-a.
Slabosti algoritma srednje promjene
Ispod su nedostaci srednjeg algoritma pomaka:
- Skupo zbog velikih značajki.
- U usporedbi s K-Means klasteriranjem to je vrlo sporo.
- Izlaz algoritma ovisi o širini opsega parametara.
- Izlaz ovisi o veličini prozora.
Zaključak
Iako je to izravan pristup koji se prije svega koristio za rješavanje problema vezanih za segmentaciju slike, grupiranje. To je relativno sporije od K-Means i računski je skupo.
Preporučeni članci
Ovo je vodič za algoritam Srednje pomake. Ovdje raspravljamo o problemima u vezi sa segmentacijom slike, grupiranjem, prednostima i dvije funkcije kernela. Možete i proći kroz naše druge povezane članke da biste saznali više -
- K- znači algoritam klasteriranja
- KNN algoritam u R
- Što je genetski algoritam?
- Metode kernela
- Kernel metode u strojnom učenju
- Detaljno objašnjenje algoritma C ++