

Uvod u Pridruživanje karte u košnici
Pridruživanje karte je značajka koja se koristi u košnicama za povećanje učinkovitosti u pogledu brzine. Pridruživanje je uvjet koji se koristi za kombiniranje podataka iz 2 tablice. Dakle, kad izvedemo normalno spajanje, posao se šalje zadatku Reduciranje karte koji glavni zadatak dijeli na 2 stupnja - „Stadij karte“ i „Smanjivanje stupnja“. Stupanj Map (Tema karte) interpretira ulazne podatke i vraća izlazni stupanj u fazi smanjenja u obliku parova ključ-vrijednost. Zatim slijedi kroz fazu izmjene, gdje se razvrstavaju i kombiniraju. Reduktor uzima ovu sortiranu vrijednost i dovršava posao spajanja.
Tablica se može u memoriju učitati u potpunosti unutar mapiranja i bez upotrebe postupka Map / Reductor. Čita podatke iz manje tablice i pohranjuje ih u heš tablicu unutar memorije, a zatim ih serializira u datoteku hash memorije čime značajno smanjuje vrijeme. Također je poznata kao Map Side Join in košnica. U osnovi uključuje spajanje između 2 tablice pomoću samo faze Map i preskakanjem faze Reduce. Primjećuje se smanjenje vremena u izračunavanju vaših upita ako redovito koriste pridruživanje male tablice.
Sintaksa za pridruživanje karte u košnici
Ako želimo upitnik za pridruživanje izvesti pomoću pridruživanja karte, tada u specifikaciji kao u nastavku moramo navesti ključnu riječ "/ * + MAPJOIN (b) * /":
>SELECT /*+ MAPJOIN(c) */ * FROM tablename1 t1 JOIN tablename2 t2 ON (t1.emp_id = t2.emp_id);
Za ovaj primjer moramo stvoriti 2 tablice s imenima namename1 i tablename2 koje imaju 2 stupca: emp_id i emp_name. Jedna bi trebala biti veća datoteka, a jedna manja.
Prije pokretanja upita moramo dolje navedeni entitet postaviti na true:
hive.auto.convert.join=true
Upit za pridruživanje za pridruživanje karti je napisan kao gore, a rezultat koji dobivamo je:
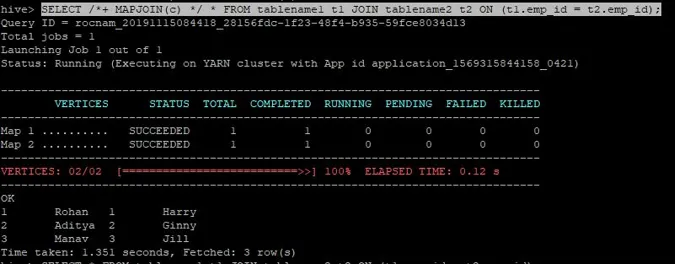
Upit je završen za 1.351 sekundi.
Primjeri pridruživanja karte u košnici
Evo dolje navedenih primjera
1. Primjer pridruživanja na karti
Za ovaj primjer stvorimo 2 tablice pod nazivom table1 i table2 sa 100 i 200 zapisa. Dolje možete uputiti naredbu i snimke zaslona za njihovo izvršavanje:
>CREATE TABLE IF NOT EXISTS table1 ( emp_id int, emp_name String, email_id String, gender String, ip_address String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");
>CREATE TABLE IF NOT EXISTS table2 ( emp_id int, emp_name String) row format delimited fields terminated BY ', ' tblproperties("skip.header.line.count"="1");

Sada učitavamo zapise u obje tablice koristeći naredbe ispod:
>load data local inpath '/relativePath/data1.csv' into table table1;
>load data local inpath '/relativePath/data2.csv' into table table2;
Izvršimo uobičajen upit za pridruživanje karte na njihovim ID-ima kao što je prikazano u nastavku i provjerimo koliko je vremena potrebno za istu:
>SELECT /*+ MAPJOIN(table2) */ table1.emp_name, table1.emp_id, table2.emp_id FROM table1 JOIN table2 ON table1.emp_name = table2.emp_name;
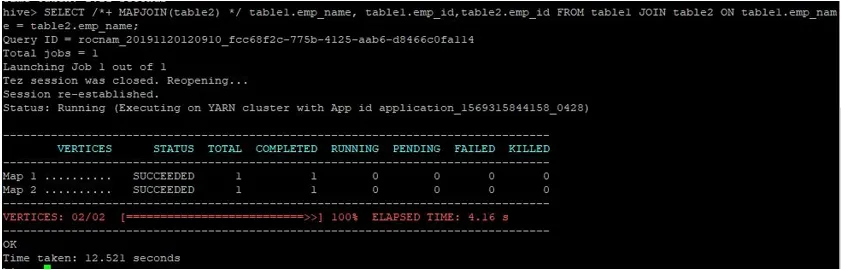
Kao što vidimo, uobičajeni upit za pridruživanje karte trajao je 12.521 sekundi.
2. Primjer pridruživanja kašike karata
Koristite sada da se Bucket-map pridruži za izvođenje istog. Postoji nekoliko ograničenja koja se moraju pridržavati za kantu:
- Kopče se mogu međusobno spajati samo ako je ukupna kanta bilo koje jedne tablice višestruka od broja kanti u drugoj tablici.
- Za obavljanje kante moraju imati zakopane stolove. Stoga stvorimo isto.
Slijede naredbe koje se koriste za izradu skupljenih tablica table1 i table2:
>>CREATE TABLE IF NOT EXISTS table1_buk (emp_id int, emp_name String, email_id String, gender String, ip_address String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ';
>CREATE TABLE IF NOT EXISTS table2_buk ( emp_id int, emp_name String) clustered by(emp_name) into 8 buckets row format delimited fields terminated BY ', ' ;

U ove izbačene tablice također ćemo umetnuti iste zapise iz tablice1:
>insert into table1_buk select * from table1;
>insert into table2_buk select * from table2;
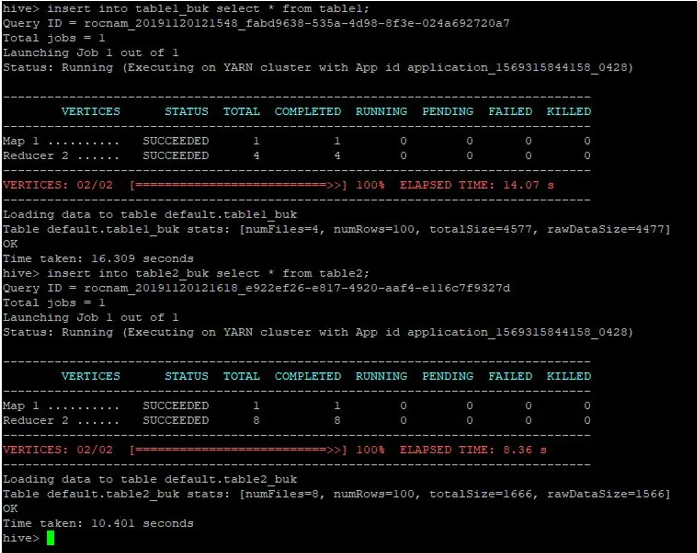
Sada kada imamo naše 2 tablice s buketima, napravimo pridruživanje mape s njima. Prva tablica ima 4 kante dok druga tablica ima 8 kanti stvorenih u istom stupcu.
Da bi upit za pridruživanje kašike karte funkcionirao, trebali bismo postaviti donji entitet na true u košnici:
set hive.optimize.bucketmapjoin = true
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
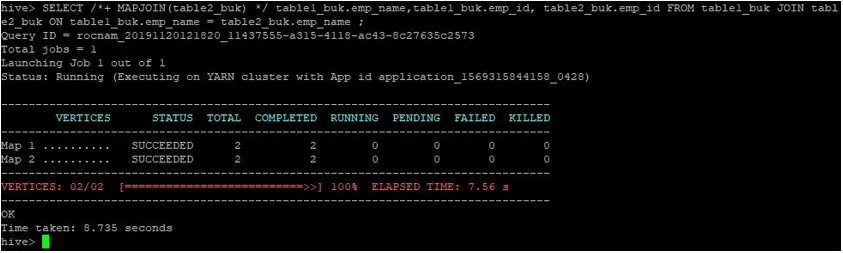
Kao što vidimo, upit je završen za 8.735 sekundi što je brže od uobičajenog pridruživanja karte.
3. Poredaj primjer pridruživanja karte spojenog spremnika (SMB)
SMB se može izvoditi na skupljenim tablicama s istim brojem kanta i ako je potrebno sortirati i staviti u svezane stupove. Razina Mapper-a se pridružuje tim kantama na odgovarajući način.
Kao i u pridruživanju Bucket-karte, postoje 4 kante za table1 i 8 kanti za table2. Za ovaj primjer, napravit ćemo drugu tablicu s 4 kante.
Da bismo pokrenuli SMB upit, trebamo postaviti sljedeća svojstva košnice kao što je prikazano u nastavku:
Hive.input.format = org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
hive.optimize.bucketmapjoin = istina;
hive.optimize.bucketmapjoin.sortedmerge = istina;
Za izvršavanje pridruživanja SMB potrebno je razvrstati podatke prema stupovima za pridruživanje. Stoga prepisujemo podatke u tablicu 1, kao što je dolje navedeno:
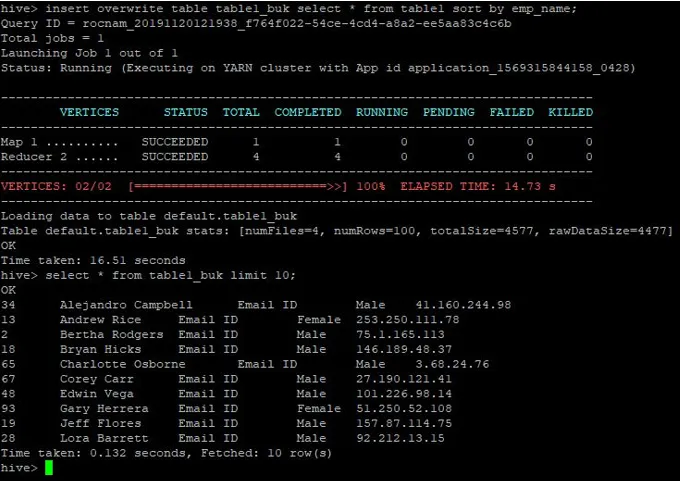
>insert overwrite table table1_buk select * from table1 sort by emp_name;
Podaci su sada sortirani što se može vidjeti na snimci zaslona u nastavku:
Također ćemo prepisati podatke u izrezanu tablicu2 kao što slijedi:
>insert overwrite table table2_buk select * from table2 sort by emp_name;

Izvedimo spajanje za iznad 2 tablice na sljedeći način:
>SELECT /*+ MAPJOIN(table2_buk) */ table1_buk.emp_name, table1_buk.emp_id, table2_buk.emp_id FROM table1_buk JOIN table2_buk ON table1_buk.emp_name = table2_buk.emp_name ;
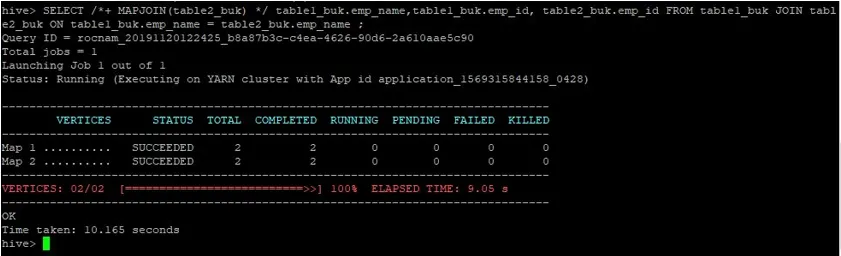
Vidimo da je upitu potrajalo 10.165 sekundi, što je opet bolje od uobičajenog pridruživanja karte.
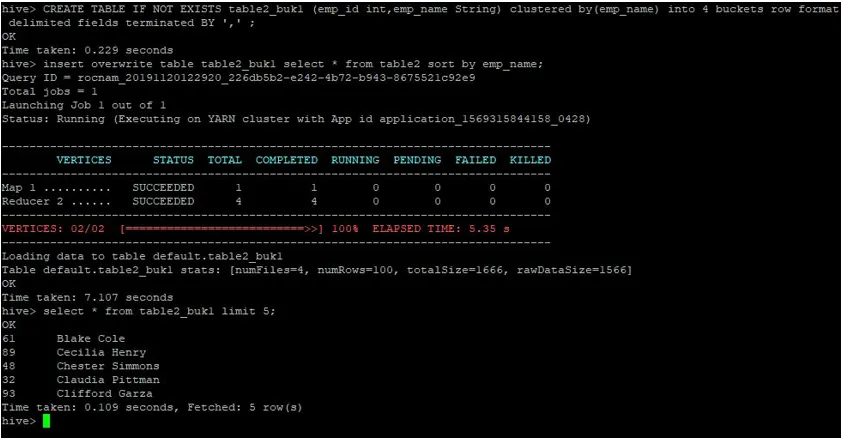
Napravimo sada drugu tablicu za table2 sa 4 kante i istim podacima sortiranim s em_name.
>CREATE TABLE IF NOT EXISTS table2_buk1 (emp_id int, emp_name String) clustered by(emp_name) into 4 buckets row format delimited fields terminated BY ', ' ;
>insert overwrite table table2_buk1 select * from table2 sort by emp_name;
S obzirom na to da sada imamo obje tablice s 4 kante, ponovo izvršimo upit za pridruživanje.
>SELECT /*+ MAPJOIN(table2_buk1) */table1_buk.emp_name, table1_buk.emp_id, table2_buk1.emp_id FROM table1_buk JOIN table2_buk1 ON table1_buk.emp_name = table2_buk1.emp_name ;
Upit je ponovo zauzeo 8.851 sekundi od uobičajenog upita za pridruživanje na karti.
prednosti
- Spajanje karata smanjuje vrijeme potrebno za procese sortiranja i spajanja koji se odvijaju u mješanju i smanjuje faze, smanjujući na taj način troškove.
- Povećava učinkovitost izvedbe zadatka.
Ograničenja
- Ista tablica / pseudonim nije dopušteno koristiti za spajanje različitih stupaca u istom upitu.
- Upit za pridruživanje karte ne može pretvoriti cjelovita vanjska spajanja u pridruživanje na strani karte.
- Spajanje karata može se izvesti samo kad je jedan od stolova dovoljno mali da se može uklopiti u memoriju. Stoga se ne može izvesti tamo gdje su podaci tablice ogromni.
- Pridruživanje lijeve moguće je učiniti pridruživanjem karte samo kad je desna veličina tablice mala.
- Desno spajanje moguće je izvesti na pridruživanju karte samo kad je veličina lijeve tablice mala.
Zaključak
Pokušali smo uključiti najbolje moguće točke Map Join u Hive. Kao što smo vidjeli gore, spajanje na strani karte najbolje funkcionira kada jedna tablica ima manje podataka, tako da se posao brzo dovršava. Vrijeme potrebno za ovdje prikazane upite ovisi o veličini skupa podataka, stoga je ovdje prikazano vrijeme samo za analizu. Spajanje karata lako se može implementirati u aplikacijama u stvarnom vremenu jer imamo ogromne podatke i na taj način pomažemo u smanjenju mrežnog I / O prometa.
Preporučeni članci
Ovo je vodič za Map Join in Hive. Ovdje smo raspravljali o primjerima Map Join u košnici zajedno s prednostima i ograničenjima. Možete pogledati i sljedeći članak da biste saznali više -
- Pridružuje se košnici
- Ugrađene funkcije košnice
- Što je košnica?
- Naredbe košnica