
Uvod u ojačavanje učenja
Ojačavanje učenja je vrsta strojnog učenja i stoga je također dio umjetne inteligencije, kad se primjenjuje na sustave, sustavi izvode korake i uče na temelju rezultata koraka kako bi postigli složeni cilj koji je sustav postavljen za postizanje.
Shvatite ojačavanje učenja
Pokušajmo pod djelovanjem učenja ojačanja s 2 jednostavna slučaja upotrebe:
Slučaj 1
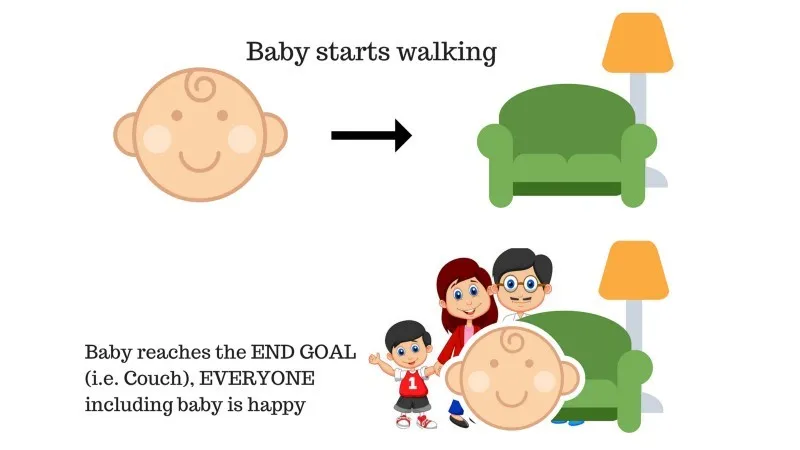
U obitelji postoji dijete i ona je tek počela hodati i svi su prilično zadovoljni zbog toga. Jednog dana, roditelji pokušavaju postaviti cilj, pustimo dijete da stigne na kauč i vidimo je li dijete u stanju to učiniti.
Rezultat slučaja 1: Beba uspješno stiže u setnju i tako su svi u obitelji sretni što to vide. Odabrani put sada dolazi s pozitivnom nagradom.
Bodovi: Nagrada + (+ n) → Pozitivna nagrada.
Izvor: https://images.app.goo.gl/pGCXJ1N1bzLAer126
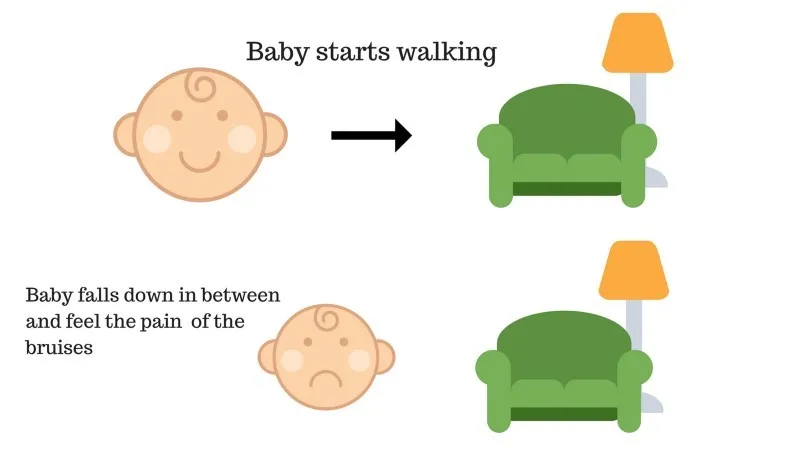
Slučaj # 2
Beba nije uspjela doći do kauča i dijete je propalo. To boli! Što bi možda mogao biti razlog? Na putu do kauča mogu postojati neke prepreke, a dijete je palo na prepreke.
Rezultat slučaja 2: Beba pada na neke prepreke i plače! Oh, bilo je loše, naučila je da sljedeći put ne upadnem u zamku prepreka. Odabrani put sada dolazi s negativnom nagradom.
Bodovi: Nagrade + (-n) → Negativna nagrada.
Izvor: https://images.app.goo.gl/FRfd8cUqrQRLe6sZ7
Sada smo vidjeli slučajeve 1 i 2, učenje pojačanja, u konceptu, čini isto, osim što nije ljudsko, već se izvodi računski.
Korištenje koraka za pojačanje
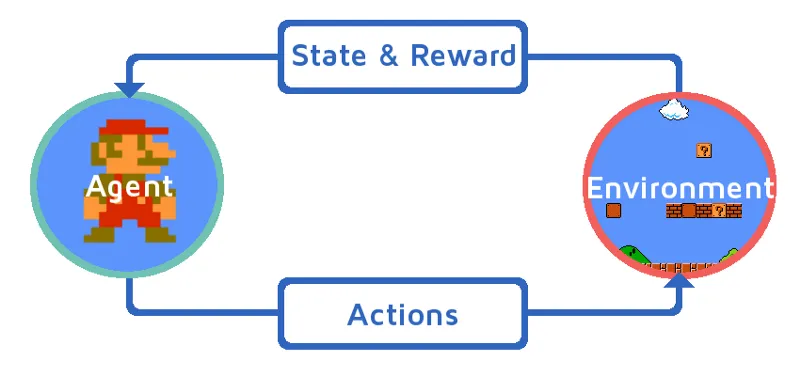
Razumijemo učenje ojačanja tako da postupno uvedemo sredstvo za pojačanje. U ovom primjeru, naš agent za učenje pojačanja je Mario koji će naučiti samostalno igrati:
Izvor: https://images.app.goo.gl/Kj44uvBzWzMw1QzE9
- Trenutno stanje Mario igre okruženje je S_0. Jer igra još nije započela i Mario je na svom mjestu.
- Zatim započinje igra i Mario kreće, Mario tj. RL agent poduzima i djeluje, recimo A_0.
- Sada je stanje okruženja za igru postalo S_1.
- Također, agentu RL-a, tj. Mariou je dodijeljeno neko pozitivno nagradu, R_1, vjerojatno zato što je Mario još uvijek živ i nije bilo opasnosti.
Sada će se gornja petlja nastaviti pokretati sve dok Mario konačno ne umre ili Mario ne dostigne svoje odredište. Ovaj će model kontinuirano izlaziti akcije, nagrade i stanja.
Nagrade za maksimizaciju
Cilj učvršćivanja učenja je povećati nagrade uzimajući u obzir i neke druge čimbenike poput popusta na nagrade; ukratko ćemo objasniti što se podrazumijeva pod popustom uz pomoć ilustracije.
Kumulativna formula za snižene nagrade je:
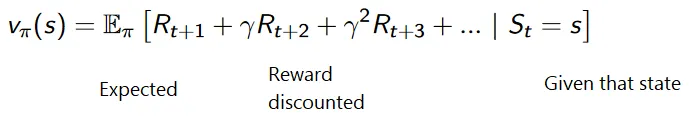
Nagrade s popustom
Shvatimo to na primjeru:
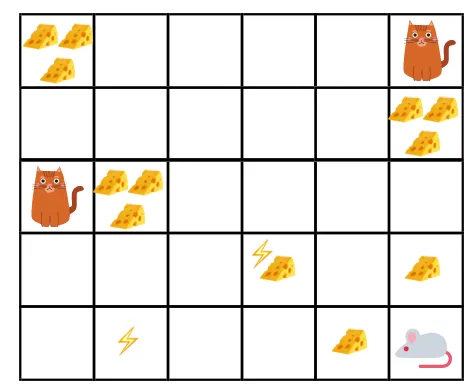
- Na slici je cilj: miš u igri mora pojesti što više sira prije nego što ga mačka pojede ili bez elektrošokovanja.
- Sada možemo pretpostaviti da što smo bliži mački ili električnoj zamci, veća je vjerojatnost da će miš pojesti ili šokirati.
- To podrazumijeva, čak i ako imamo puni sir u blizini strujnog udara ili u blizini mačke, što je rizičnije ići tamo, bolje je jesti sir koji se nalazi u blizini kako ne bi bilo rizika.
- Dakle, iako imamo jedan "blok1" sira koji je pun i udaljen je od mačke i bloka strujnog udara i drugi "blok2", koji je pun, ali je blizu mačke ili bloka strujnog udara, kasniji blok sira, tj. "block2", bit će diskontiran u nagradama od prethodnog.
Izvor: https://images.app.goo.gl/8QrH78FjmRVs5Wxk8
Izvor: https://cdn-images-1.medium.com/max/800/1*l8wl4hZvZAiLU56hT9vLlg.png.webp
Vrste usavršavanja učenja
Slijede dvije vrste učenja ojačanja s njihovim prednostima i nedostacima:
1. pozitivno
Kada se snaga i učestalost ponašanja povećaju zbog pojave nekog određenog ponašanja, to je poznato kao pozitivno učvršćivanje učenja.
Prednosti: Performanse su maksimizirane i promjena ostaje dulje vrijeme.
Nedostaci: Rezultati se mogu umanjiti ako imamo previše pojačanja.
2. negativan
To je jačanje ponašanja, uglavnom zbog toga što negativni pojam nestaje.
Prednosti: Ponašanje se povećava.
Nedostaci: Samo minimalno ponašanje modela može se postići uz učenje negativnog pojačanja.
Gdje se treba koristiti ojačavajućim učenjem?
Stvari koje se mogu učiniti pomoću pojačanog učenja / primjera. Ovo su područja u kojima se ovih dana koristi pojačanje:
- Zdravstvo
- Obrazovanje
- Igre
- Računalni vid
- Poslovna uprava
- Robotika
- Financije
- NLP (Obrada prirodnog jezika)
- transport
- energija
Karijere u poboljšanju učenja
Zaista postoji izvješće s web mjesta za posao, budući da je RL grana Strojnog učenja, sukladno izvještaju, Strojno učenje je najbolji posao 2019. Ispod je sažetak izvještaja. Prema trenutnim trendovima, inženjeri strojnog učenja dolaze s nevjerojatnom prosječnom plaćom od 146 085 dolara i sa stopom rasta od 344 posto.
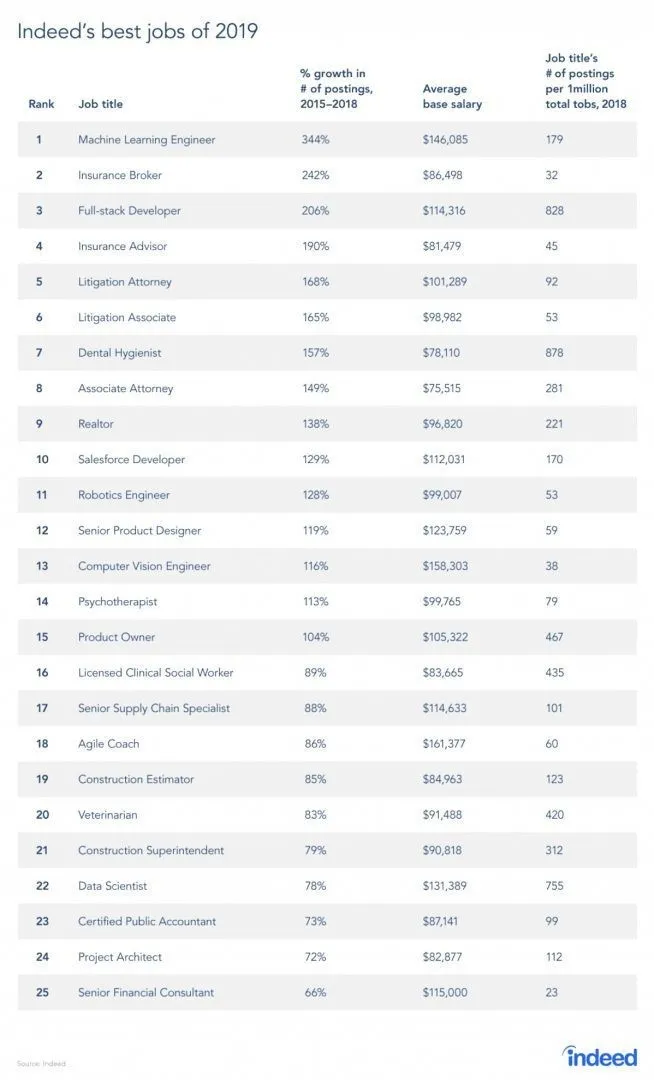
Izvor: https://i0.wp.com/www.artificialintelligence-news.com/wp-content/uploads/2019/03/indeed-top-jobs-2019-best.jpg.webp?w=654&ssl=1
Vještine za ojačavanje učenja
Ispod je vještina potrebna za učenje ojačanja:
1. Osnovne vještine
- Vjerojatnost
- statistika
- Modeliranje podataka
2. Vještine programiranja
- Osnove programiranja i informatike
- Dizajn softvera
- Moguće je primijeniti knjižnice i algoritme strojnog učenja
3. Strojno učenje jezika programiranja
- Piton
- R
- Iako postoje i drugi jezici na kojima se mogu oblikovati modeli strojnog učenja, kao što su Java, C / C ++, ali su Python i R jezici koji se najviše koriste.
Zaključak
U ovom smo članku započeli s kratkim upoznavanjem učenja o pojačanju, a zatim smo duboko zaronili u radu na RL-u i različitim čimbenicima koji su uključeni u rad RL modela. Tada smo dali nekoliko primjera iz stvarnog svijeta kako bismo još bolje shvatili temu. Na kraju ovog članka trebalo bi dobro razumjeti funkcioniranje učenja o pojačanju.
Preporučeni članci
Ovo je vodič Što je pojačano učenje ?. Ovdje ćemo raspravljati o funkciji i različitim čimbenicima koji su uključeni u razvoj modela ojačavanja učenja, s primjerima. Možete i pregledati naše druge povezane članke da biste saznali više -
- Vrste algoritama strojnog učenja
- Uvod u umjetnu inteligenciju
- Alati za umjetnu inteligenciju
- IoT platforma
- Top 6 jezika za strojno učenje