

Uvod u pridruživanje u Spark SQL-u
Kao što znamo spajanja u SQL-u koriste se za kombiniranje podataka ili redaka iz dvije ili više tablica na temelju zajedničkog polja između njih. U ovoj ćemo temi saznati nešto o Pridruži se u Spark SQL Pridružite se u Spark SQL.
U Spark SQL, Dataframe ili Dataset su tablična struktura u memoriji koja ima redove i stupce koji su raspoređeni po više čvorova. Kao i uobičajene SQL tablice, također možemo izvoditi operacije pridruživanja na Dataframeu ili skupu podataka prisutnih u Spark SQL-u na temelju zajedničkog polja između njih.
U SQL-u su dostupne različite vrste operacija pridruživanja. Ovisno o slučaju poslovne uporabe, mi odlučujemo o operaciji pridruživanja. U sljedećem ćemo dijelu prikazati svaku vrstu pridruživanja sa primjerom.
Vrste pridruživanja u Spark SQL-u
Slijede različite vrste pridruživanja dostupnih u Spark SQL-u:
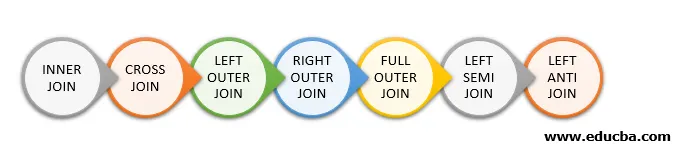
- UNUTAR PRIDRUŽITE SE
- CROSS PRIDRUŽITE se
- LEVO VANJU PRIDRUŽITE se
- PRAVO SPOLJITE PRIJAVITE se
- POTPUNO PRIDRUŽITE SE
- LIJEVI SEMI PRIDRUŽITE se
- LIJEVI ANTI PRIDRUŽITE se
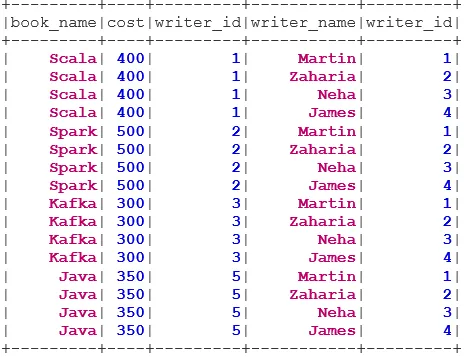
Primjer stvaranja podataka
Sljedeće podatke koristit ćemo za prikaz različitih vrsta pridruživanja:
Skup podataka knjige:
case class Book(book_name: String, cost: Int, writer_id:Int)
val bookDS = Seq(
Book("Scala", 400, 1),
Book("Spark", 500, 2),
Book("Kafka", 300, 3),
Book("Java", 350, 5)
).toDS()
bookDS.show()

Skup podataka Writer:
case class Writer(writer_name: String, writer_id:Int)
val writerDS = Seq(
Writer("Martin", 1),
Writer("Zaharia " 2),
Writer("Neha", 3),
Writer("James", 4)
).toDS()
writerDS.show()

Vrste pridruživanja
Ispod se spominje 7 različitih vrsta pridruživanja:
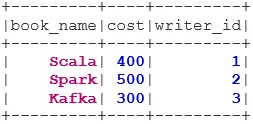
1. UNUTARNJI PRIDRUŽITE SE
INNER JOIN vraća skup podataka koji ima redove koji imaju podudarne vrijednosti u obje skupove podataka, tj. Vrijednost zajedničkog polja bit će ista.
val BookWriterInner = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "inner")
BookWriterInner.show()

2. KROZ PRIDRUŽITE se
CROSS JOIN vraća skup podataka koji je broj redova u prvom skupu podataka pomnožen s brojem redaka u drugom skupu podataka. Takav se rezultat naziva kartezijanski proizvod.
Preduvjet: Za korištenje unakrsnog spajanja, spark.sql.crossJoin.enabled mora biti postavljen na true. U suprotnom, izuzeće će biti bačeno.
spark.conf.set("spark.sql.crossJoin.enabled", true)
val BookWriterCross = bookDS.join(writerDS)
BookWriterCross.show()
3. LEVO VANJU PRIDRUŽITE se
LEFT OUTER JOIN vraća skup podataka koji ima sve redove s lijeve baze podataka i podudarne retke s desnog skupa podataka.
val BookWriterLeft = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftouter")
BookWriterLeft.show()

4. PRAVO UNUTRAJ PRIDRUŽITE SE
RIGHT OUTER JOIN vraća skup podataka koji ima sve redove s desnog skupa podataka, a podudarne retke s lijeve baze podataka.
val BookWriterRight = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "rightouter")
BookWriterRight.show()

5. PUNA VANJSKA PRIDRUŽITE SE
FULL OUTER JOIN vraća skup podataka koji ima sve redove kada postoji podudaranje ili u lijevom ili u desnom skupu podataka.
val BookWriterFull = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "fullouter")
BookWriterFull.show()

6. LEVI SEMI PRIDRUŽITE se
LEFT SEMI JOIN vraća skup podataka koji ima sve redove s lijeve baze podataka koji imaju odgovarajuću korespondenciju u desnom skupu podataka. Za razliku od LEFT OUTER JOIN, vraćeni skup podataka u LEFT SEMI JOIN sadrži samo stupce s lijevog skupa podataka.
val BookWriterLeftSemi = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftsemi")
BookWriterLeftSemi.show()
7. LIJEVI ANTI PRIDRUŽITE se
ANTI SEMI JOIN vraća skup podataka koji ima sve redove s lijevog skupa podataka koji ne odgovaraju u odgovarajućem skupu podataka. Sadrži i samo stupce s lijevog skupa podataka.
val BookWriterLeftAnti = bookDS.join(writerDS, bookDS("writer_id") === writerDS("writer_id"), "leftanti")
BookWriterLeftAnti.show()

Zaključak - Pridružite se Spark SQL-u
Podaci za spajanje jedna su od najčešćih i najvažnijih operacija za ispunjavanje slučaja naše poslovne upotrebe. Spark SQL podržava sve osnovne vrste spajanja. Prilikom pridruživanja, trebamo razmotriti i performanse jer mogu zahtijevati velike mrežne prijenose ili čak stvoriti skupove podataka izvan naših mogućnosti za obradu. Za poboljšanje performansi Spark koristi SQL alat za optimizaciju kako bi ponovno odredio ili pritisnuo filtre. Iskra također ograničava opasne spojeve i. e KROZ PRIDRUŽITE se. Za upotrebu unakrsnog spajanja, spark.sql.crossJoin.enabled mora biti izričito postavljen na true.
Preporučeni članci
Ovo je vodič za pridruživanje u Spark SQL-u. Ovdje smo sa primjerom razgovarali o različitim vrstama pridruživanja dostupnih u Spark SQL-u. Možete pogledati i sljedeći članak.
- Vrste pridruživanja u SQL-u
- Tablica u SQL-u
- SQL upit za umetanje
- Transakcije u SQL-u
- PHP filteri | Kako provjeriti korisnički unos pomoću različitih filtera?