
Razlika između strojnog učenja i prediktivne analitike
Strojno učenje je područje informatike, koje ovih dana raste i skače. Nedavni napredak u hardverskim tehnologijama koji je rezultirao velikim porastom računske snage poput GPU-a (grafičke procesorske jedinice) i napretkom u neuronskim mrežama, strojno je učenje postalo jeziva riječ. U osnovi, koristeći tehnike strojnog učenja, možemo izraditi algoritme za vađenje podataka i vidjeti važne skrivene informacije iz njih. Prediktivna analitika također je dio domene strojnog učenja koji je ograničen za predviđanje budućeg ishoda na temelju podataka na temelju prethodnih obrazaca. Iako se prediktivna analitika koristi već više od dva desetljeća, uglavnom u bankarskom i financijskom sektoru, primjena strojnog učenja u posljednje vrijeme dobiva na značaju algoritmima poput otkrivanja predmeta iz slika, tekstualne klasifikacije i sustava preporuka.
Strojno učenje
Strojno učenje interno koristi statistiku, matematiku i osnove informatike kako bi stvorio logiku za algoritme koji mogu klasificirati, predviđati i optimizirati u realnom vremenu, kao i u batch načinu rada. Razvrstavanje i regresija su dvije glavne klase problema strojnog učenja. Upoznajmo detaljno i strojno učenje i prediktivnu analitiku.
Klasifikacija
Pod tim skupinama problema, skloni smo razvrstati objekt na temelju njegovih različitih svojstava u jednu ili više klasa. Na primjer, razvrstavanje klijenta u banku da ispunjava uvjete za kredit za stanovanje ili ne na temelju njegove kreditne povijesti. Obično bismo za kupca imali dostupne podatke o transakcijama kao što su njegova dob, prihod, školska pozadina, radno iskustvo, industrija u kojoj radi, broj izdržavanih obitelji, mjesečni troškovi, prethodni zajmovi ako postoje, njegov obrazac potrošnje, kreditna povijest itd. … i na osnovu tih podataka skloni bismo izračunati treba li mu dati zajam ili ne.
Postoji mnogo standardnih algoritama strojnog učenja koji se koriste za rješavanje problema s klasifikacijom. Logistička regresija jedna je od takvih metoda, vjerojatno najraširenija i većinom poznata, također najstarija. Pored toga, imamo i neke od najnaprednijih i najkompliciranijih modela, od stabla odluka do slučajne šume, AdaBoost, XP boost, vektorske strojeve za podršku, naivnu kožu i neuralnu mrežu. Od posljednjih nekoliko godina duboko učenje izbija u prvi plan. Za razvrstavanje slika obično se koristi neuronska mreža i duboko učenje. Ako postoji stotina tisuća slika mačaka i pasa, a želite napisati kôd koji automatski može razdvojiti slike mačaka i pasa, možda biste htjeli potražiti metode dubokog učenja poput konvolucijske neuronske mreže. Torch, kafić, protok senzora itd. Neke su od popularnih knjižnica u pythonu koje omogućuju duboko učenje.
Za mjerenje točnosti regresijskih modela koriste se metrike poput lažne pozitivne stope, lažno negativne stope, osjetljivosti itd.
Regresija
Regresija je još jedna klasa problema u strojnom učenju gdje pokušavamo predvidjeti kontinuiranu vrijednost varijable umjesto klase za razliku od klasičnih problema. Regresijske se tehnike obično koriste za predviđanje cijene dionica, prodajne cijene kuće ili automobila, potražnje za određenim predmetom, itd. Kada svojstva vremenske serije također uđu u igru, problemi regresije postaju vrlo zanimljivi za rješavanje. Linearna regresija s uobičajenim najmanje kvadratom jedan je od klasičnih algoritama strojnog učenja u ovoj domeni. Za uzorak temeljen na vremenskim serijama koriste se ARIMA, eksponencijalni pomični prosjek, ponderirani pomični prosjek i jednostavan pomični prosjek.
Za mjerenje točnosti regresijskih modela koriste se metrike poput srednje kvadratne pogreške, apsolutne srednje kvadratne pogreške, kvadratne pogreške korijena itd.
Prediktivna analitika
Postoje područja preklapanja između strojnog učenja i prediktivne analitike. Dok se uobičajene tehnike poput logističke i linearne regresije podliježu i strojnom učenju i prediktivnoj analitici, napredni algoritmi poput stabla odlučivanja, slučajna šuma itd. U osnovi su strojno učenje. Pod prediktivnom analitikom cilj problema ostaje vrlo uzak gdje je namjera izračunati vrijednost određene varijable u budućem trenutku. Prediktivna analitika jako je opterećena dok je strojno učenje više spoj statistike, programiranja i matematike. Tipični analitičar predviđanja troši svoje vrijeme računajući t kvadrat, f statistiku, Innova, chi kvadrat ili obični najmanje kvadrat. Pitanja poput da li su podaci normalno distribuirani ili iskrivljeni, treba li koristiti distribuciju učenika ili koristiti krivulju zvona, treba li alfa uzimati 5% ili 10% greške stalno. Oni u detalje traže vraga. Inženjer strojnog učenja ne muči se mnogim od ovih problema. Njihova glavobolja je potpuno drugačija. Oni su zaglavljeni u poboljšanju točnosti, smanjenju lažno pozitivnih stopa, rukovanju vanjima, normalizaciji raspona ili k validaciji pregiba.
Prediktivni analitičar uglavnom koristi alate poput excela. Scenario ili traženje cilja su im omiljeni. Povremeno koriste VBA ili micros i jedva pišu dugotrajni kod. Inženjer strojnog učenja sve svoje vrijeme provodi pišući komplicirani kod izvan uobičajenog razumijevanja, koristi alate poput R, Python, Saas. Programiranje je njihov glavni posao, popravljanje grešaka i testiranje različitih krajolika svakodnevna rutina.
Te razlike također donose veliku razliku u njihovoj potražnji i plaći. Dok su jučerašnji analitičari prediktivni, strojno učenje je budućnost. Tipični inženjer strojnog učenja ili podatkovni znanstvenik (kako se danas uglavnom nazivaju) plaćaju 60-80% više od tipičnog softverskog inženjera ili prediktivnog analitičara po tom pitanju i oni su ključni pokretač u današnjem svijetu omogućenom tehnologijom. Uber, Amazon i sada osobni automobili mogući su i samo zbog njih.
Usporedba između strojnog učenja i prediktivne analitike (Infographics)
Ispod je top 7 usporedbe između strojnog učenja i predviđanja Analytics
Tablica usporedbe strojnog učenja i prediktivne analitike
Ispod je detaljno objašnjenje Strojnog učenja vs Predictive Analytics
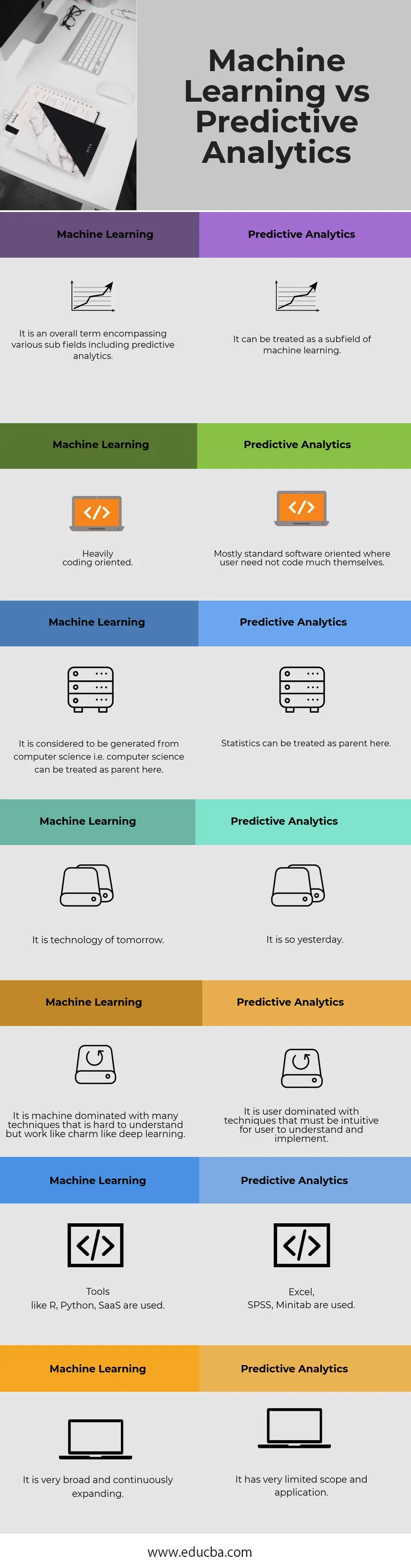
| Strojno učenje | Prediktivna analitika |
| To je sveukupni pojam koji obuhvaća različita potpolja uključujući prediktivnu analitiku. | Može se tretirati kao potpolje strojnog učenja. |
| Jako orijentirano na kodiranje. | Uglavnom standardno softverski orijentirani tamo gdje korisnik ne mora puno kodirati sebe |
| Smatra se da nastaje iz informatike, tj. Računalna znanost ovdje se može smatrati roditeljem. | Ovdje se statistika može smatrati roditeljem. |
| To je tehnologija sutrašnjice. | Tako je bilo jučer. |
| To je stroj kojim dominiraju mnoge tehnike koje je teško razumjeti, ali djeluju poput šarma poput dubokog učenja. | To je dominiranje korisnika s tehnikama koje moraju biti intuitivne da bi ih korisnik mogao razumjeti i implementirati. |
| Koriste se alati poput R, Python, SaaS. | Koriste se Excel, SPSS, Minitab. |
| Vrlo je široka i kontinuirano se širi. | Ima vrlo ograničen opseg i primjenu. |
Zaključak - Strojno učenje i predviđanje analitike
Iz gornje rasprave i o Strojnom učenju i Prediktivnoj analitici jasno je da je prediktivna analitika u osnovi potpolje strojnog učenja. Strojno učenje je svestranije i sposobno je riješiti širok raspon problema.
Preporučeni članak
Ovo je vodič za strojno učenje i prediktivnu analitiku, njihovo značenje, uporedbu između glave, ključne razlike, tablicu usporedbe i zaključak. Možete pogledati i sljedeće članke da biste saznali više -
- Saznajte velike podatke o strojnom učenju
- Razlika između znanosti o podacima i strojnog učenja
- Usporedba između Predictive Analytics i Data Science
- Analiza podataka protiv prediktivne analize - koja je korisna