

Uvod u iskopavanje podataka
Ovo je metoda vađenja podataka koja se koristi za smještanje podatkovnih elemenata u njihove slične skupine. Klaster je postupak dijeljenja objekata podataka na potklase. Kvaliteta klastera ovisi o metodi koju smo koristili. Klasteriranje se naziva i segmentacija podataka jer su velike grupe podataka podijeljene prema sličnosti.
Što je grupiranje u iskopavanju podataka?
Klasteriranje je grupiranje određenih objekata na temelju njihovih karakteristika i sličnosti. Što se tiče kopanja podataka, ova metodologija dijeli podatke koji su najprikladniji za željenu analizu pomoću posebnog algoritma pridruživanja. Ova analiza omogućuje da objekt ne bude dio ili strogo dio klastera, što se naziva tvrdom podjelom ove vrste. Međutim, glatke particije sugeriraju da svaki objekt u istom stupnju pripada grupi. Mogu se stvoriti određenije podjele poput objekata iz više klastera, jedan klaster može biti prisiljen na sudjelovanje ili se u grupnim odnosima može stvoriti čak i hijerarhijska stabla. Ovaj se datotečni sustav može postaviti na različite načine na temelju različitih modela. Ovi različiti algoritmi primjenjuju se na svaki model, razlikujući njihova svojstva kao i njihove rezultate. Dobar algoritam klastera može identificirati klaster neovisan o obliku klastera. Postoje 3 osnovne faze algoritma grupiranja koji su prikazani kao dolje
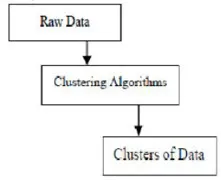
Klasteriranje algoritama u procesu podataka
Ovisno o nedavno opisanim modelima klastera, mnogi se klasteri mogu koristiti za dijeljenje informacija u skup podataka. Treba reći da svaka metoda ima svoje prednosti i nedostatke. Odabir algoritma ovisi o svojstvima i prirodi skupa podataka.
Metode klasteriranja za vađenje podataka mogu se prikazati u nastavku
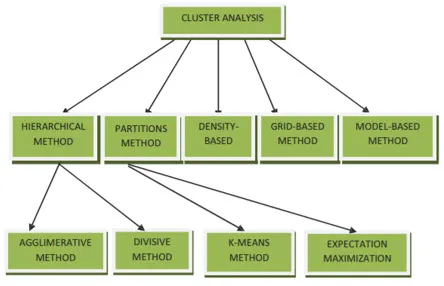
- Metoda koja se temelji na particiji
- Metoda koja se temelji na gustoći
- Metoda zasnovana na centroidima
- Hijerarhijska metoda
- Metoda zasnovana na mreži
- Metoda utemeljena na modelu
1. Metoda na temelju podjele
Algoritam particije dijeli podatke na više podskupina.
Pretpostavimo da algoritam za particioniranje gradi particiju podataka jer su k i n predmeti prisutni u bazi podataka. Stoga će svaka particija biti prikazana kao k ≤ n.
To daje ideju da se klasifikacija podataka nalazi u k skupinama, što može biti prikazano u nastavku
Na slici 1 prikazane su izvorne točke u grupiranju

Na slici 2 prikazano je grupiranje particija nakon primjene algoritma
Ovo ukazuje da svaka grupa ima najmanje jedan objekt, kao i svaki objekt, koji mora pripadati točno jednoj grupi.
2. Metoda zasnovana na gustoći
Ovi algoritmi proizvode klastere na određenom mjestu na temelju velike gustoće sudionika u skupu podataka. Skuplja neki pojam raspona za članove grupe u klasterima do razine standardne gustoće. Ovakvi procesi mogu biti slabiji u otkrivanju površinskih područja grupe.
3. Metoda temeljena na centroidima
Gotovo svaki klaster upućuje vektor vrijednosti u ovoj vrsti tehnike osnivanja os. U odnosu na druge klastere, svaki je objekt dio klastera s minimalnom razlikom vrijednosti. Broj klastera bi trebao biti unaprijed definiran, a to je najveći problem algoritama ovog tipa. Ova je metodologija najbliža temi identifikacije i široko se koristi za probleme optimizacije.
4. Hijerarhijska metoda
Metoda će stvoriti hijerarhijsku dekompoziciju datog skupa podataka. Na temelju formiranja hijerarhijske dekompozicije možemo klasificirati hijerarhijske metode. Ova metoda je dana na sljedeći način
- Aglomerativni pristup
- Divizijski pristup
Aglomerativni pristup također je poznat i kao pristup gumbom. Ovdje započinjemo sa svakim objektom koji čini zasebnu skupinu. Nastavlja sa spajanjem objekata ili skupina bliskih zajedno
Podjela pristupa također je poznata i kao pristup odozgo prema dolje. Počinjemo sa svim objektima u istom klasteru. Ova je metoda kruta, tj. Nikad je ne može poništiti nakon fuzije ili podjele
5. Metoda koja se temelji na mreži
Mrežne metode temelje se na prostoru objekta umjesto dijeljenja podataka u mrežu. Mreža se dijeli na temelju karakteristika podataka. Ovom metodom lako je upravljati ne numeričkim podacima. Redoslijed podataka ne utječe na podjelu mreže. Važna prednost mrežnog modela nudi bržu izvedbu.
Prednosti hijerarhijskog klasteriranja su sljedeće
- Primjenjivo je na bilo koju vrstu atributa.
- Omogućuje fleksibilnost koja se odnosi na razinu zrnatosti.
6. Metoda utemeljena na modelu
Ova metoda koristi hipotezirani model zasnovan na raspodjeli vjerojatnosti. Klasteriranjem funkcije gustoće, ova metoda locira klastere. Odraz je prostorne raspodjele podatkovnih točaka.
Primjena klasteriranja u Rudarstvu podataka
Klasteriranje može pomoći u mnogim poljima kao što su Biologija, Biljke i životinje klasificirane po njihovim svojstvima kao i u marketingu. Klasteriranje će pomoći identificiranju korisnika određenih podataka o kupcima sa sličnim postupcima. U mnogim primjenama, kao što su istraživanje tržišta, prepoznavanje uzoraka, obrada podataka i slika, klastera analiza se koristi u velikom broju. Klasteriranje također može pomoći oglašivačima u svojoj korisničkoj bazi da pronađu različite grupe. Njihove grupe kupaca mogu se definirati kupovinom obrazaca. U biologiji se koristi za određivanje biljnih i životinjskih taksonomija, za kategorizaciju gena slične funkcionalnosti i za uvid u strukture svojstvene populaciji. U zemaljskoj bazi podataka o promatranju, klasteriranje također olakšava pronalaženje područja slične upotrebe u zemlji. Pomaže u identificiranju skupina kuća i stanova prema vrsti, vrijednosti i odredištu kuća. Grupiranje dokumenata na webu također je od pomoći za otkrivanje informacija. Analiza klastera je alat za stjecanje uvida u distribuciju podataka radi promatranja karakteristika svakog klastera kao funkcije vađenja podataka.
Zaključak
Klasteriranje je važno u iskopavanju podataka i njegovoj analizi. U ovom smo članku vidjeli kako se klasteriranje može provesti primjenom različitih algoritama klasteriranja, kao i njegovom primjenom u stvarnom životu.
Preporučeni članak
Ovo je vodič za ono što je klasteriranje u Rudarstvu podataka. Ovdje smo razgovarali o konceptima, definiciji, značajkama, primjeni klasteriranja u Rudarstvu podataka. Možete i proći naše druge predložene članke da biste saznali više -
- Što je obrada podataka?
- Kako postati analitičar podataka?
- Što je SQL ubrizgavanje?
- Definicija što je SQL Server?
- Pregled arhitekture rudarstva podataka
- Klasteriranje u strojnom učenju
- Hijerarhijski algoritam klasteriranja
- Hijerarhijsko grupiranje | Aglomerativno i podjeljeno grupiranje