

Uvod u Hadoop arhitekturu
Hadoop arhitektura je okvir otvorenog koda koji pomaže u jednostavnoj obradi velikih skupova podataka. To pomaže u stvaranju aplikacija koje obrađuju ogromne podatke s većom brzinom. Koristi distribuirane koncepte računanja gdje su podaci raspoređeni po različitim čvorovima klastera. Aplikacije izgrađene pomoću Hadoopa koriste robna računala. Ta su računala lako dostupna na tržištu po povoljnim cijenama. Ovaj rezultat postiže veću računsku snagu uz nisku cijenu. Svi podaci prisutni u Hadoopu nalaze se na HDFS umjesto u lokalnom datotečnom sustavu. HDFS je distribuirani datotečni sustav Hadoop. Ovaj se model temelji na lokalnosti podataka gdje se računska logika šalje čvorovima prisutnima u klasteru koji sadrži podatke. Ta logika nije ništa drugo nego logika koja sastavlja program.
Hadoop arhitektura
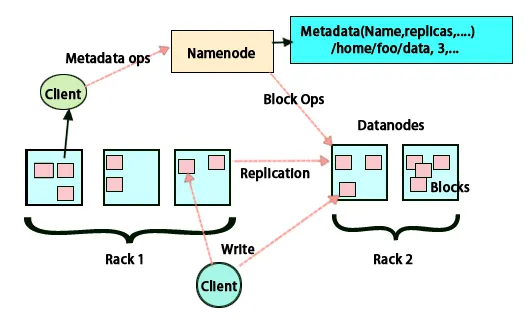
Osnovna ideja ove arhitekture je da se cijelo pohranjivanje i obrada vrši u dva koraka i na dva načina. Prvi korak je obrada koja se vrši programiranjem smanjenja karata, a drugi korak je pohrana podataka koji se rade na HDFS. Ima master-slave arhitekturu za pohranu i obradu podataka. Glavni čvor za pohranu podataka u Hadoopu je čvor imena. Tu je i glavni čvor koji nadgleda i paralelno obrađuje podatke koristeći Hadoop Map Reduce. Robovi su ostali strojevi u grupi Hadoop koji pomažu u pohrani podataka i također obavljaju složene proračune. Svakom slavenskom čvoru dodijeljen je alat za praćenje zadataka, a podatkovni čvor ima alat za praćenje poslova koji pomaže u pokretanju procesa i njihovoj učinkovitoj sinkronizaciji. Ova vrsta sustava može se postaviti bilo u oblaku ili na lokaciji. Čvor Name jedna je točka neuspjeha kada se ne radi u načinu visoke dostupnosti. Hadoop arhitektura također ima mogućnost održavanja stand by naziva čvora kako bi se zaštitio sustav od kvarova. Ranije su postojali sekundarni imenski čvorovi koji su djelovali kao sigurnosna kopija kad je primarni čvor imena bio dolje.
FSimage i Uredi dnevnik
FSimage i Uređivanje dnevnika osiguravaju postojanost metapodataka datotečnog sustava da budu u toku sa svim podacima i čvor imena sprema metapodatke u dvije datoteke. Te su datoteke FSimage i zapisnik za uređivanje. Zadatak FSimagea je zadržati cjelovit snimak datotečnog sustava u zadanom vremenu. Promjene koje se u sustavu neprekidno vrše potrebno je voditi evidenciju. Ove inkrementalne promjene poput preimenovanja ili dodavanja detalja datoteci pohranjuju se u zapisnik za uređivanje. Okvir pruža bolju opciju, a ne stvaranje novog FSimage-a svaki put, bolju opciju mogućnost pohranjivanja podataka dok nova datoteka za FSimage. FSimage stvara novi snimak svaki put kada se izvrše promjene Ako čvor Name ne uspije, on može vratiti prethodno stanje. Čvor sekundarnog imena također može ažurirati svoju kopiju kad god postoje promjene u FSimage-u i uređivanje dnevnika. Dakle, osigurava da iako je ime čvora dolje, u prisutnosti sekundarnog čvora imena neće doći do gubitka podataka. Čvor naziva ne zahtijeva da te slike moraju biti ponovno učitane na sekundarnom čvoru imena.
Replikacija podataka
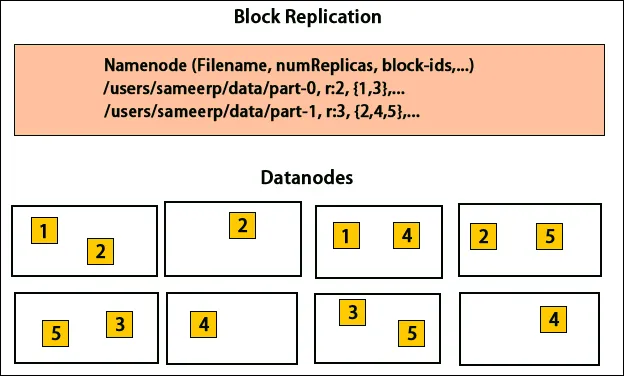
HDFS je dizajniran za brzu obradu podataka i pružanje pouzdanih podataka. Pohranjuje podatke na strojevima i u velikim klasterima. Sve datoteke su pohranjene u nizu blokova. Ti se blokovi ponavljaju zbog tolerancije greške. Veličinu bloka i faktor replikacije mogu odlučiti korisnici i konfigurirati prema potrebama korisnika. Faktor replikacije je prema zadanim postavkama 3. Faktor replikacije može se odrediti u trenutku stvaranja datoteke i može se kasnije promijeniti. Sve odluke vezane za te replike donose imenski čvor. Čvor imena stalno šalje otkucaje srca i izvješće o blokadi u redovitim intervalima za sve čvorove podataka u klasteru. Primanje otkucaja srca podrazumijeva da čvor podataka ispravno radi. Izvješće o bloku određuje popis svih blokova prisutnih na čvoru podataka.
Postavljanje replika
Postavljanje replika vrlo je važan zadatak u Hadoopu zbog pouzdanosti i performansi. Svi različiti blokovi podataka nalaze se na različitim stalcima. Implementacija postavljanja replika može se provesti prema pouzdanosti, dostupnosti i iskorištavanju propusne mreže. Skup računala može se raširiti na različite police. Na isti stalak ne mogu se postaviti više od dva čvora. Treća replika trebala bi biti postavljena na drugi stalak kako bi se osigurala veća pouzdanost podataka. Dva čvora na stalak komuniciraju putem različitih prekidača. Čvor imena ima ID stalak za svaki čvor podataka. No postavljanje svih čvorova na različite stalke sprječava gubitak bilo kakvih podataka i omogućuje korištenje propusne širine s više regala. Također smanjuje promet između reketa i poboljšava performanse. Također, vjerojatnost kvara stalak je vrlo manja u odnosu na slučaj kvara na čvoru. Smanjuje propusnost zbirne mreže kada se podaci očitavaju iz dva jedinstvena stalka, a ne iz tri.
Smanjivanje karte
Map Reduct koristi se za obradu podataka koji se pohranjuju na HDFS. Piše distribuirane podatke u distribuirane aplikacije što osigurava učinkovitu obradu velike količine podataka. Obrađuju se na velikim grozdovima i zahtijevaju robu koja je pouzdana i neispravna. Jezgra smanjenja karata mogu biti tri operacije poput mapiranja, prikupljanja parova i izmještanja dobivenih podataka.
Zaključak - Hadoop arhitektura
Hadoop je okvir otvorenog koda koji pomaže u sustavu otpornosti na pogreške. Može pohraniti velike količine podataka i pomaže u pohrani pouzdanih podataka. Dva dijela za pohranu podataka u HDFS i njihovu obradu putem mapa smanjuju pomoć u pravilnom i efikasnom radu. Ima arhitekturu koja pomaže u upravljanju svim blokovima podataka, a također ima i najnoviju kopiju pohranjivanjem u FSimage i uređivanjem zapisnika. Faktor replikacije pomaže i u kopiranju podataka i vraćanju podataka kad god dođe do greške. HDFS također premješta uklonjene datoteke u mapu otpad za optimalno korištenje prostora.
Preporučeni članci
Ovo je vodič za Hadoop arhitekturu. Ovdje smo razgovarali o arhitekturi, reduciranju karata, smještanju replika, replikaciji podataka. Možete i proći naše druge predložene članke da biste saznali više -
- Postanite Hadoop programer
- Uvod u Android
- Što je Tableau? | Pregled
- Što je MapReduce u Hadoopu?