
Uvod u nazadno uklanjanje
Kako čovjek i stroj udaraju prema digitalnoj evoluciji, različiti strojevi računaju kako bi postali ne samo osposobljeni, već i pametno obučeni, kako bi izašli s boljim prepoznavanjem objekata u stvarnom svijetu. Takva tehnika uvedena ranije pod nazivom "nazadno uklanjanje" koja je željela favorizirati neophodne značajke, istodobno iskorjenjujući nužna svojstva kako bi se omogućila bolja optimizacija u stroju. Čitava stručnost prepoznavanja predmeta od strane stroja je proporcionalna značajkama koje razmatra.
Karakteristike koje na predviđenom izlazu nemaju referencu moraju se izbaciti iz stroja i to zaključiti uklanjanjem unatrag. Dobra preciznost i vremenska složenost Strojinog prepoznavanja bilo kojeg stvarnog riječnog predmeta ovise o njegovom učenju. Dakle, eliminacija unatrag igra svoju krutu ulogu u odabiru značajki. Izračunava brzinu ovisnosti obilježja o zavisnoj varijabli te pronalazi značaj njezine pripadnosti u modelu. Da bi to akreditirao, provjerava obračunatu stopu sa standardnom razinom značajnosti (recimo 0, 06) i donosi odluku o odabiru značajki.
Zašto povlačimo zaostalo uklanjanje ?
Nebitne i suvišne osobine pokreću složenost strojne logike. Nepotrebno proždire vrijeme i resurse modela. Dakle, spomenuta tehnika igra kompetentnu ulogu da krivotvori model na jednostavan. Algoritam njeguje najbolju verziju modela optimiziranjem njegovih performansi i iskorištavanjem potrošnih imenovanih resursa.
To smanjuje najmanje značajne značajke modela, što uzrokuje buku u odlučivanju regresije. Nerelevantne osobine objekta mogu dovesti do pogrešne klasifikacije i predviđanja. Nebitne značajke entiteta mogu predstavljati neusklađenost modela u odnosu na druga značajna obilježja drugih objekata. Eliminacija unatrag podupire uklapanje modela u najbolji slučaj. Stoga se za uklanjanje unatrag preporučuje korištenje u modelu.
Kako primijeniti nazadno uklanjanje?
Eliminacija unatrag započinje svim varijablama značajki, testirajući je sa ovisnom varijablom prema odabranom kriteriju modela. Počinje iskorjenjivati one varijable koje pogoršavaju dozu regresije. Ponavljajte ovo brisanje dok model ne postigne dobru prilagodbu. Ispod su koraci za uklanjanje unatrag:
Korak 1: Odaberite odgovarajuću razinu značaja koja će se nalaziti u modelu stroja. (Uzmi S = 0, 06)
Korak 2: Napunite sve dostupne neovisne varijable modela s obzirom na ovisnu varijablu i nagib računala i presretanje da biste nacrtali liniju regresije ili liniju uklapanja.
Korak 3: Pređite sa svim nezavisnim varijablama koje imaju najveću vrijednost (Uzmi I), jednu po jednu, i nastavite sa sljedećim zdravicom: -
a) Ako sam> S, izvedite 4. korak.
b) Ostalo pobačaj i model je savršen.
Korak 4: Uklonite odabranu varijablu i povećajte prolaz.
Korak 5: Ponovno forsirajte model i ponovno izračunajte nagib i presretanje odgovarajuće linije uz preostale varijable.
Navedeni koraci sažeti su u odbacivanje onih značajki čija je stopa značajnosti iznad odabrane vrijednosti značajnosti (0, 06) kako bi se izbjeglo prekomjerno klasificiranje i prekomjerna upotreba resursa koji su zabilježeni kao velika složenost.
Zasluge i mane zaostalog uklanjanja
Evo nekoliko zasluga i nedostataka zaostalog uklanjanja u nastavku detaljno:
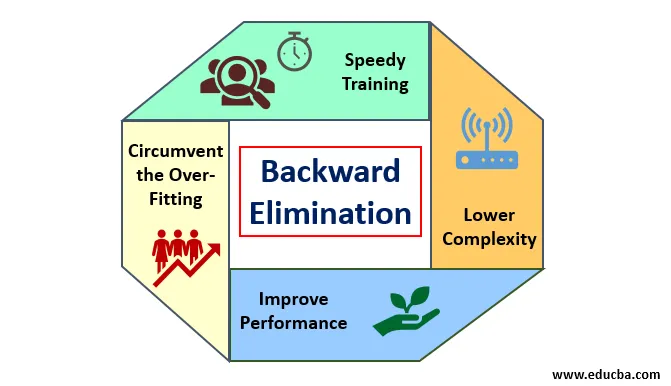
1. Zasluge
Zasluge nazadnog uklanjanja su sljedeće:
- Brzi trening: Stroj je obučen s nizom dostupnih značajki uzorka koje se rade u vrlo kratkom vremenu ako se iz modela uklone nebitne značajke. Brzo osposobljavanje skupa podataka dolazi u obzir samo kada se model bavi značajnim značajkama i isključuje sve varijable buke. Crta jednostavnu složenost za trening. No, model se ne smije podvrgnuti nedovoljnoj prilagodbi, što se događa zbog nedostatka značajki ili neadekvatnih uzoraka. Značajka uzorka trebala bi biti obilna u modelu za najbolju klasifikaciju. Vrijeme potrebno za obuku modela trebalo bi biti manje uz održavanje točnosti klasifikacije i ne smije biti varijabla pod-predviđanja.
- Donja složenost: Složenost modela događa se velikom ako model razmatra opseg značajki, uključujući buku i nepovezane značajke. Model troši mnogo prostora i vremena za obradu takvog raspona značajki. To može povećati stopu točnosti prepoznavanja uzoraka, ali brzina može sadržavati i buku. Da biste se riješili tako velike složenosti modela, algoritam za uklanjanje unatrag igra potrebnu ulogu povlačenjem neželjenih značajki iz modela. Pojednostavljuje logiku obrade modela. Samo je nekoliko bitnih značajki dovoljno da se napravi dobar fit koji sadrži razumnu točnost.
- Poboljšanje performansi: Učinkovitost modela ovisi o mnogim aspektima. Model je podvrgnut optimizaciji korištenjem uklanjanja unatrag. Optimizacija modela je optimizacija skupa podataka koji se koristi za obučavanje modela. Učinkovitost modela izravno je proporcionalna brzini optimizacije koja se oslanja na učestalost značajnih podataka. Proces uklanjanja unatrag nije namijenjen pokretanju promjena iz bilo kojeg niskofrekventnog predviđača. Ali izmjene započinje samo iz podataka visokih frekvencija, jer uglavnom složenost modela ovisi o tom dijelu.
- Zaobilazite prekomjerno uklapanje: Situacija s prekomjernim uklapanjem događa se kada je model dobio previše skupova podataka i provodi se klasifikacija ili predviđanje u kojima su neki predviđali buku drugih klasa. U ovom je opremanju model trebao dati neočekivano visoku točnost. Pri prekomjernom uklapanju model možda neće uspjeti klasificirati varijablu zbog zbrke stvorene u logici zbog prevelikih uvjeta. Tehnika uklanjanja unatrag smanjuje suvišnu značajku kako bi se zaobišao slučaj prekomjernog namještanja.
2. Demeriti
Slaboći nazadnog uklanjanja su sljedeći:
- U nazadnoj metodi eliminacije ne može se saznati koji je prediktor odgovoran za odbacivanje drugog prediktora zbog njegovog dosega do beznačajnosti. Na primjer, ako prediktor X ima neki značaj koji je bio dovoljan da ostane u modelu nakon dodavanja Y prediktora. No, značaj X postaje zastario kada u model dođe neki drugi prediktor Z. Dakle, algoritam za uklanjanje unatrag ne pokazuje nikakvu ovisnost dva prediktora koji se događaju u "Tehnici odabira naprijed".
- Nakon što neki algoritam uklanjanja bilo koje značajke s modela unatrag ne može se ponovno odabrati tu značajku. Ukratko, uklanjanje unatrag nema fleksibilan pristup dodavanju ili uklanjanju značajki / prediktora.
- Norme za odabir vrijednosti značajnosti (0, 06) u modelu su nefleksibilne. Zaostalo uklanjanje nema fleksibilan postupak da se ne samo odabere, već i promijeni beznačajna vrijednost kako je potrebno kako bi se pronašao najbolji fit u odgovarajućem skupu podataka.
Zaključak
Tehnika uklanjanja unatrag realizirana je za poboljšanje performansi modela i za optimizaciju njegove složenosti. Živo se koristi u više regresija gdje se model bavi opsežnim podacima. To je jednostavan i jednostavan pristup u usporedbi s odabirom naprijed i unakrsnom validacijom u kojem je došlo do preopterećenja optimizacije. Tehnika uklanjanja unatrag inicira uklanjanje obilježja veće vrijednosti. Njegov je osnovni cilj učiniti model manje složenim i zabraniti pretjerano uklapanje situacije.
Preporučeni članci
Ovo je vodič za nazadno uklanjanje. Ovdje smo raspravljali o tome kako primijeniti uklanjanje unatrag, zajedno s zaslugama i nedostacima. Možete pogledati i sljedeće članke da biste saznali više -
- Strojno učenje hiperparametara
- Klasteriranje u strojnom učenju
- Java virtualni stroj
- Nenadzirano strojno učenje