

Uvod u Python Pandas DataFrame
Na mreži se mogu pronaći mnoga proširenja Python biblioteke, Pandas. Jedan od takvih je Panel (pan) podaci (das). Ova riječ, * Panel *, suptilno nagovještava dvodimenzionalnu strukturu podataka koja postoji u ovoj knjižnici, neizmjerno osnažujući svoje korisnike. Ova se sama struktura naziva DataFrame.
To je u osnovi matrica redaka i stupaca koja sadrži cijeli vaš skup podataka, s vrlo promišljenim opcijama indeksiranja istih. DataFrame (DF) može se zamisliti slikovito vrlo sličnim Excelovom listu. Ali ono što ga čini moćnim je jednostavnost s kojom se analitičke i transformacijske operacije mogu izvoditi na podacima pohranjenim u DataFrame.
Što je točno DataFrame Python Pandas-a?
Stranica Pydata može se uputiti za službenu definiciju.
Ako se shvati ispravno, spominje DataFrame kao stupastu strukturu, koja je sposobna pohraniti bilo koji objekt Python (uključujući i sam DataFrame) kao jednu vrijednost ćelije. (Stanica se indeksira pomoću jedinstvene kombinacije redaka i stupaca)
DataFrames se sastoji od tri osnovne stavke: podataka, redaka i stupaca.
- Podaci: Odnosi se na stvarne objekte / entitete pohranjene u ćeliji u DataFrame-u i na vrijednosti koje predstavljaju ovi entiteti. Objekt je bilo kojeg važećeg python tipa podataka, bilo ugrađenog ili definiranog od strane korisnika.
- Redovi: Reference koje se koriste za identificiranje (ili indeksiranje) određenog skupa opažanja iz kompletnih podataka pohranjenih u DataFrame-u naziva se Redovi. Da bismo to pojasnili, on koristi upotrijebljene indekse, a ne samo podatke u određenom promatranju.
- Stupci: Upućivanja koja se koriste za identificiranje (ili indeksiranje) skupa atributa za sva opažanja u DataFrame-u. Kao i u slučaju redova, oni se odnose na indeks stupaca (ili zaglavlja stupaca), a ne samo na podatke u stupcu.
Dakle, bez ikakvih dodatnih pokusa, isprobajmo nekoliko načina za stvaranje ovih nevjerojatno mocnih struktura.
Koraci za stvaranje DataFrames Python Pandas
DataFrame Python Pandas-a može se stvoriti pomoću sljedeće implementacije koda,
1. Uvoz pande
Da biste stvorili DataFrames, biblioteku pande treba uvesti (ovdje nema iznenađenja). Uvest ćemo ga s pseudonimom pd-a za referencu objekata u modulu.
Kodirati:
import pandas as pd
2. Stvaranje prvog objekta DataFrame
Nakon uvoza knjižnice, sve metode, funkcije i konstruktori dostupni su u vašem radnom prostoru. Dakle, pokušajmo stvoriti DataFrame vanilije.
Kodirati:
import pandas as pd
df = pd.DataFrame()
print(df)
Izlaz:
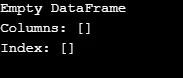
Kao što je prikazano u izlazu, konstruktor vraća prazan DataFrame.
Sada ćemo se usredotočiti na stvaranje DataFrames-a iz podataka pohranjenih u nekim vjerojatnim prikazima.
- DataFrame iz Rječnika: Recimo da imamo rječnik koji pohranjuje popis tvrtki u Software Domain i broj godina u kojima su aktivni.
Kodirati:
import pandas as pd
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Infosys', 'Directi'),
'Age':('21', '23', '38', '22') ))
print (df)
Pogledajmo reprezentaciju vraćenog DataFrame objekta ispisujući ga na konzoli.
Izlaz:

Kao što se može vidjeti, svaka se tipka rječnika tretira kao stupac u DataFrame-u, a indeksi redova generiraju se automatski počevši od 0. Prilično lako!
Recimo sada da ste mu željeli dati prilagođeni indeks umjesto 0, 1, .. 4. Trebate samo proslijediti željeni popis kao parametar konstruktoru i pande će učiniti što je potrebno.
Kodirati:
df = pd.DataFrame(
('Company':('Google', 'Amazon', 'Yahoo', 'Infosys', 'Directi'),
'Age':('21', '23', '24', '38', '22') ),
index=('Alpha', 'Beta', 'Gamma', 'Delta'))
print(df)
Izlaz:
Kompanija doba
Alpha Google 21
Beta Amazon 23
Gamma Infosys 38
Delta Directi 22
Sada možete postaviti indekse retka na bilo koju željenu vrijednost.
- DataFrame iz CSV datoteke: Kreirajmo CSV datoteku koja sadrži iste podatke kao u slučaju našeg rječnika. Nazovimo datoteku CompanyAge.csv
Google, 21
Amazon, 23
Infosys, 38
Usmjerenosti, 22
Datoteka se može učitati u podatkovni okvir (pod pretpostavkom da postoji u trenutnoj radnoj mapi) na sljedeći način.
Kodirati:
csv_df = pd.read_csv(
'CompanyAge.csv', names=('Company', 'Age'), header=None)
print(csv_df)
Izlaz:
Kompanija doba
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Postavljanje imena parametara , zaobilazeći popis vrijednosti, dodjeljuje ih kao zaglavlja stupaca istim redoslijedom kojim su prisutni na popisu. Slično tome, indeksi retka mogu se postaviti prosljeđivanjem popisa parametru indeksa, kao što je prikazano u prethodnom odjeljku. Zaglavlje = Ništa ne označava zaglavlje stupaca u datoteci podataka.
Recimo da su imena stupaca bila dio datoteke s podacima. Tada će postavljanje zaglavlja = False izvršiti traženi posao.
3. CompanyAgeWithHeader.csv
Tvrtka, dob
Google, 21
Amazon, 23
Infosys, 38
Usmjerenosti, 22
Kodeks će se promijeniti u
csv_df = pd.read_csv(
'CompanyAgeWithHeader.csv', header=False)
print(csv_df)
Izlaz:
Kompanija doba
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
- DataFrame iz datoteke Excel: Podaci se često dijele u excel datotekama jer to su najpopularniji alat koji obični ljudi koriste za Adhoc praćenje. Stoga se naša rasprava ne smije zanemariti.
Pretpostavimo da su podaci, isti kao u CompanyAgeWithHeader.csv, sada pohranjeni u CompanyAgeWithHeader.xlsx, na listu s imenom Company Age. Sljedećim kodom bit će kreiran isti DataFrame kao gore.
Kodirati:
excel_df= pd.read_excel('CompanyAgeWithHeader.xlsx', sheet_name='CompanyAge')
print(excel_df)
Izlaz:
Kompanija doba
0 Google 21
1 Amazon 23
2 Infosys 38
3 Directi 22
Kao što vidite, isti DataFrame može se stvoriti prolaskom imena datoteke i naziva lista.
Daljnje čitanje i sljedeći koraci
Prikazane metode predstavljaju vrlo mali podskup u odnosu na sve različite načine na koje se mogu stvoriti DataFrames. Oni su stvoreni s namjerom da se započnu. Svakako istražite navedene reference i pokušajte istražiti druge načine, uključujući povezivanje s bazom podataka kako biste izravno pročitali podatke u DataFrame.
Zaključak
Pandas DataFrame pokazao se kao izmjenjivač igara u svijetu Data Science i Data Analytics, kao i prikladan je za ad hoc kratkoročne projekte. Dolazi s nizom alata koji mogu s izuzetnom lakoćom rezati i urezati skup podataka. Nadamo se da će ovo poslužiti kao odskočna daska na vašem putovanju pred vama.
Preporučeni članci
Ovo je vodič za Python-Pandas DataFrame. Ovdje smo raspravljali o koracima za stvaranje podatkovnog okvira python-pandas zajedno s njegovom implementacijom koda. Možete pogledati i sljedeće članke da biste saznali više -
- Top 15 značajki Pythona
- Različite vrste skupova Python
- Top 4 vrste varijabli na Python-u
- Top 6 urednika Pythona
- Nizovi u strukturi podataka